 Julia Daimio
Julia Daimio

For all the noise around agentic AI, most agents today still suffer from a fundamental flaw: they forget everything.
Despite massive advances in models, tools, and orchestration frameworks, the majority of deployed agents remain constrained by context windows, unable to accumulate experience and build meaningful continuity across interactions. This is where persistent agentic memory infrastructure emerges: not as an optimization layer, but as a foundational shift.
Enabling agents to behave less like calculators and more like entities that learn, adapt, and improve with use is not a marginal upgrade. It is the difference between automation and autonomy.
Agents Hit the Stateless Ceiling
Over the last year, it became obvious that stateless agents don’t scale. They fail at long-running tasks, iterative workflows, and personalization - and they don’t learn from mistakes. At the same time, the rise of agent frameworks, driven by ecosystems (OpenAI, Anthropic, CrewAI, and many others), shifted focus from single prompts to persistent processes. And once agents persist, memory becomes unavoidable.
This is not a trend anymore - and it’s never been, in a sense. Here’s where things are actually going: in the next 12–24 months, memory layers will standardize across agent stacks, while the evaluation of memory quality will become a core metric.
But what even qualifies as a real agentic memory layer, and how is it different from traditional RAG with added storage? This is how Nicolò Boschi @nicoloboschi, Lead Software Engineer at Vectorize @Vectorizeio, answers this question:
“Traditional RAG is a search system. Memory systems should understand your data and connect the dots. They should be able to provide context to correctly answer questions that require multi-hop reasoning, temporal, entity, and knowledge evolution; traditional search systems can't do this.”
Over time, agents will actively manage and compress their own memory, and “memory-native” architectures will replace RAG-heavy hacks. The competition here is definitely shifting from model quality to system memory quality.
Where Persistent Memory Is Already Delivering: Memory-as-a-Service
A strong example here is Zep, which has evolved into a dedicated long-term memory layer for agents, not just a vector store. Zep provides conversation-aware memory storage, automatic summarization of long histories, temporal context tracking, and many more features. What makes the project relevant is that it handles the hardest problem: keeping memory useful over time, not just storing it. Instead of dumping raw embeddings, it continuously compresses and restructures interaction history, making retrieval both faster and more accurate.
Agentic Frameworks: Memory is Becoming Default
Frameworks like LlamaIndex and LangChain have moved from optional memory modules to core memory abstractions.
LlamaIndex enables composable pipelines combining structured data, embeddings, and retrieval strategies. LangChain, especially through LangGraph, introduces stateful execution, where memory is embedded into the agent’s runtime rather than injected per request. Meanwhile, AutoGPT exposes the limits of naive memory - simple vector recall quickly degrades under long-horizon tasks. The takeaway is clear: memory is not solved, but it is now non-optional.
Benchmarking and Evaluation
Memory is only valuable if it works, and until recently, there was no serious way to measure that. The good thing is that’s changing. Several benchmarks now target agentic memory performance, not just recall:
- LongMemEval by @DiWu0162 evaluates how well systems retain and use information across extended, multi-turn interactions;
- MemoryAgentBench by @YzhuML measures retrieval accuracy, conflict resolution, and long-range reasoning in agent workflows;
- Mem2ActBench tests whether agents can use memory to complete tasks, not just retrieve it;
- HELM by David Hall @dlwh from The Stanford Center for Research on Foundation Models increasingly incorporates long-context and memory-relevant evaluation scenarios;
- Hindsight by @Vectorizeio is one of the first benchmarks focused on production-grade memory systems, evaluating retrieval relevance, latency, cost-performance tradeoffs, and real-world agent memory behavior. What makes Hindsight particularly important is that it moves beyond academic evaluation and asks a more practical question: does this memory system actually work under real constraints?
Top Persistent AI Agent Memory Systems (April 2026)
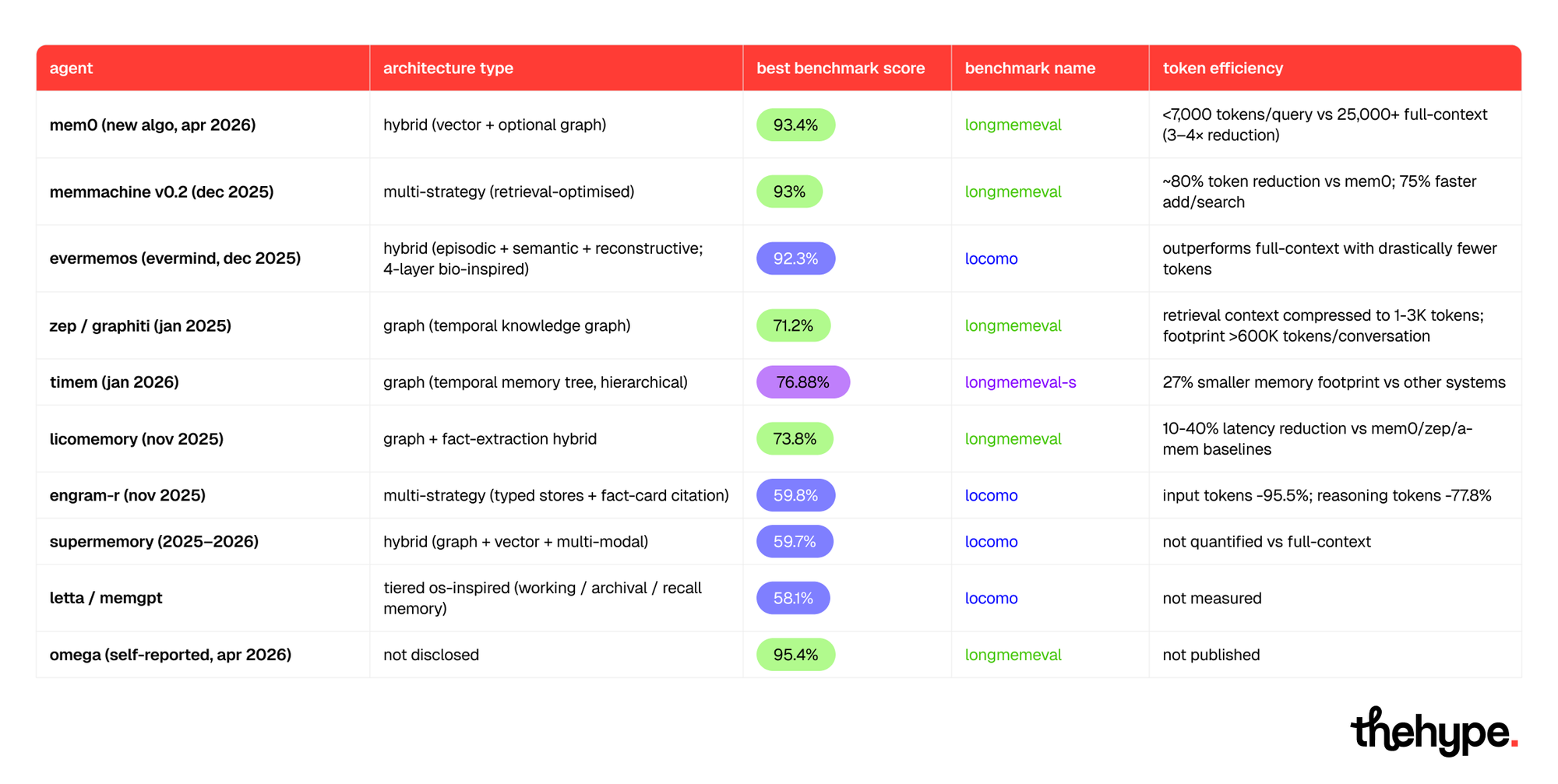
This is a good moment to mention once again: even the most advanced benchmarks are not perfect. Nicolò Boschi states that something important that all the benchmarks still fail to measure is the opportunity to "grow your knowledge along with your agent":
“I believe the new benchmarks should measure "how much and at what cost my agent becomes better at understanding my requests and grabbing the right context the more I use it" - there's no benchmark for it, yet.”
Best Memory Setups Being Shipped Right Now
LangGraph + Redis uses Redis as both a checkpoint store and a fast memory layer for agents. It handles short-term state, allowing agents to resume workflows, and can also support vector-style retrieval via Redis stack tools like RedisVL. This is one of the clearest production patterns for stateful agents.
In LangGraph + PostgreSQL, the latter is used as the durable memory backbone. It stores agent checkpoints so workflows can be resumed across sessions, making it a standard choice for long-running agents. LangGraph explicitly recommends database-backed persistence (including Postgres) for production deployments.
A hybrid memory system based on LangGraph, PostgreSQL, and pgvector uses LangGraph for agent execution and state management, PostgreSQL for durable checkpoints and long-term persistence, and pgvector to add semantic search directly inside the database. It’s a common “single-database + vector extension” approach because it avoids adding a separate vector DB while still enabling embedding-based retrieval over past agent interactions.
Memory Is the Real Moat
The agents might be noisy, but the signal is clear: most systems today still don’t remember well, and therefore, don’t improve. The winners in this space will not be the ones with the best prompts or the fastest wrappers. But what in particular will be different - and what should be different for the whole field to move forward?
“Memory and the agent harness are tied together. They are different systems, but they must have a clear interaction contract,” reflects Nicolò Boschi. - “The memory system is the storage of the agent - all the rest is 'intelligence'/reasoning and ad-hoc tools. The win point will happen when someone can close the learning loop between the agent actions and outcomes and the memory with a self-learning system.”
What else? The sector will be led by the projects and builders with high-quality memory selection, efficient retrieval and compression, and tight integration between memory and action; basically, the systems that learn continuously. Because once agents start remembering properly, the entire dynamic changes.


