 Nick Trenkler
Nick Trenkler

for two years, the constraint was simple: not enough gpu supply. now the workload itself is changing, and with it the bottleneck.
ai systems are moving from generating answers to executing tasks. that shift is measurable:
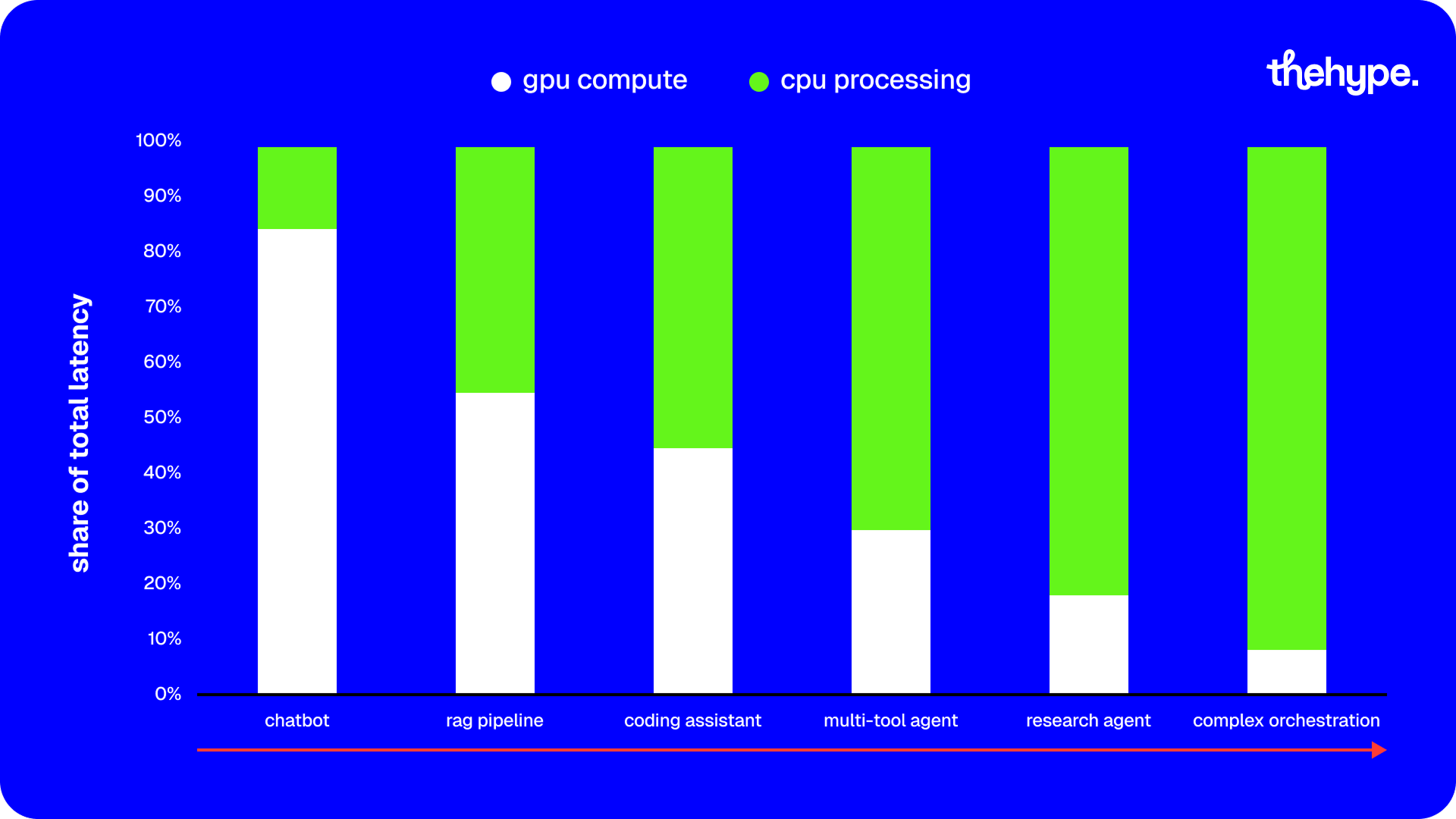
- in agent-style workloads, up to 80–90% of total latency sits on the cpu side (tool calls, orchestration, data movement).
- cpu can also account for ~40–45% of total energy consumption in these systems.
at the same time, gpu utilization is increasingly limited by how fast data and tasks are fed into them, not by raw compute availability.
morgan stanley put it directly in 2026: “the computing bottleneck is shifting toward cpu and memory” as workflows become more action-heavy.
this is not theoretical. it’s already visible in how systems behave.
what actually changed
early ai workloads were simple. one request, one response. most of the work was inside the model.
now look at a typical agent: it plans, calls multiple tools, reads and writes memory, validates outputs, retries failures, and chains steps together. instead of one operation, you get dozens.
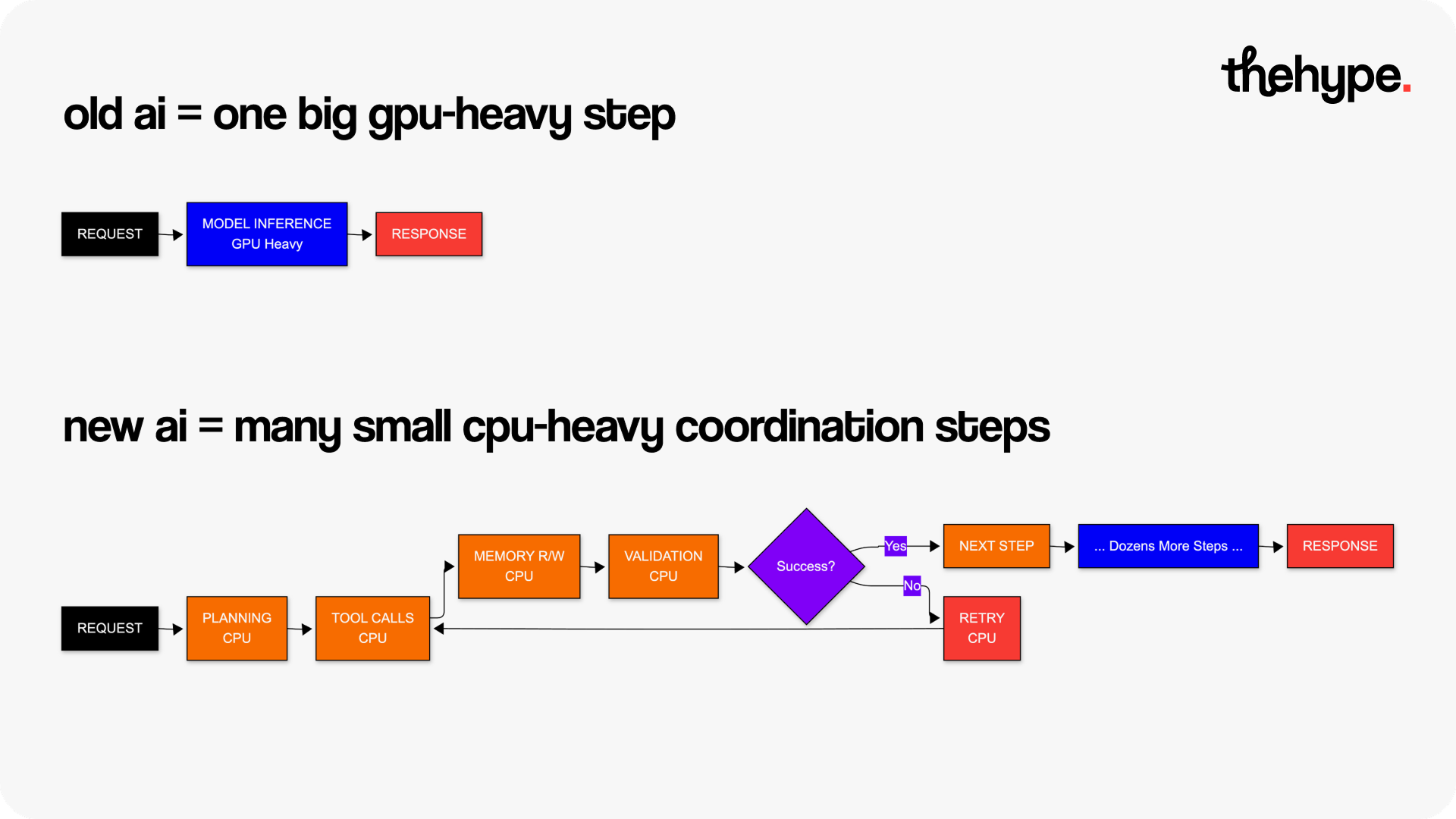
each of those steps is lightweight individually but expensive in coordination. that coordination runs on cpu. so the system profile flips. less time spent generating tokens, more time spent managing work.
gpu vs cpu in plain terms
if you’re building, this is the only distinction that matters.
gpu is where the model runs. it handles parallel math and generates outputs. it’s optimized for throughput.
cpu is where everything else happens. it executes code, calls apis, schedules tasks, moves data, manages state, and coordinates workflows.
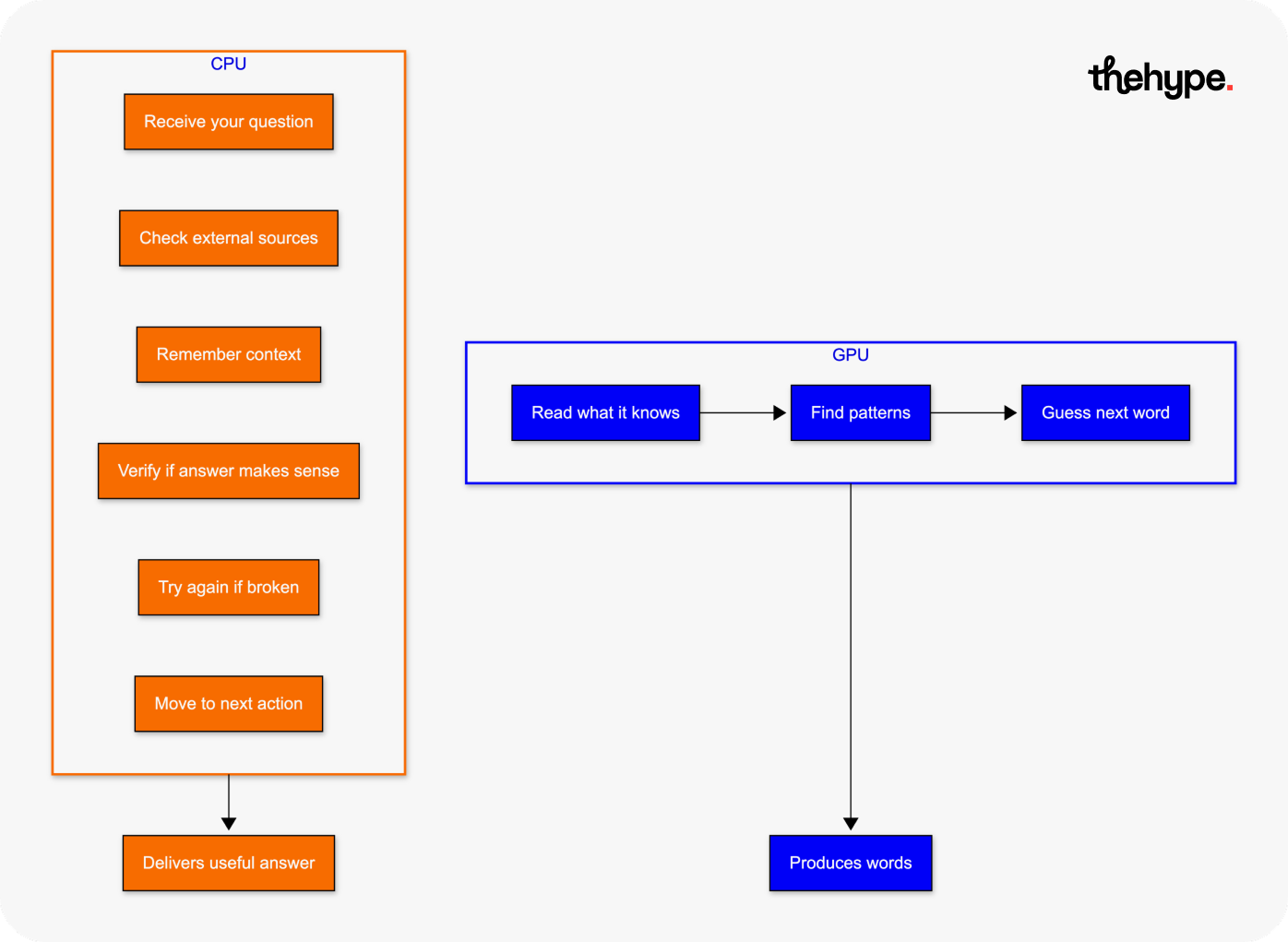
gpu produces the answer. cpu makes the answer usable.
when you move from chatbots to agents, you increase the share of “everything else.”
the numbers behind the shift
- latency moves outside the model. in agent systems, up to 80-90% of total latency comes from orchestration, tool calls, and data movement – not inference.
- cpu becomes a major energy driver. cpu can account for up to ~44% of total energy usage in agent pipelines.
- agent adoption is accelerating. roughly one-third of organizations are scaling agents in at least one function, with another ~39% experimenting.
- cpu supply is tightening. server cpu lead times have stretched from 1-2 weeks to 8-12 weeks, with some orders reaching up to six months under ai demand.
- infra is still gpu-heavy – but shifting. modern ai servers typically run 4-8 gpus per cpu, and this ratio is expected to compress as agent workloads scale. nvidia’s newest rubin systems already move closer to 2:1.
the direction is consistent across sources: more actions, more coordination, more pressure on cpu and memory.
why this becomes a bottleneck
gpus scale well with parallel work. cpus don’t scale the same way for coordination-heavy workloads.
agents create exactly the kind of load cpus struggle with many small operations, frequent waiting on external systems, constant state management, and high orchestration overhead.
that leads to a new failure mode. not model quality, not token limits, but system throughput.
you can have available gpu capacity and still be blocked because the system cannot coordinate tasks fast enough. this is already showing up as gpu underutilization caused by data and orchestration delays.
what this means in costs
today, a simple model call can cost a few cents. but agent workflows turn one request into 10–30 steps, with tool calls, retries, and execution overhead. in practice, this pushes cost per task from ~$0.01-0.03 for chat to ~$0.10-0.50+ for agents, and even higher in complex workflows.
the important shift is that costs are no longer driven only by tokens. orchestration, retries, and execution time – all cpu-heavy – start to dominate. and while model pricing continues to drop, system-level costs are growing with every additional step.
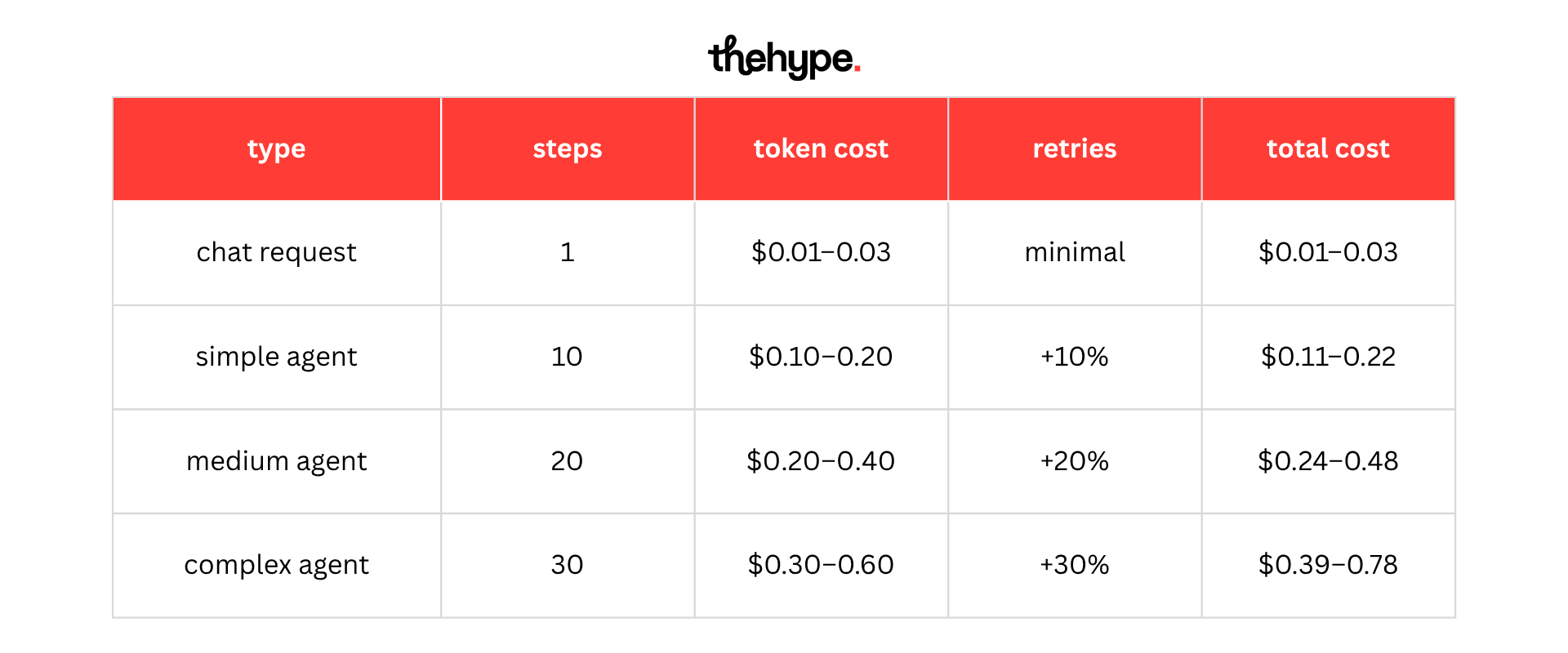
if this layer is not optimized, agents don’t get cheaper over time. they get more capable, but also more expensive to run. which means the real constraint for builders is no longer just intelligence, but whether the economics of their system actually hold.
gpu problem = engine power
cpu problem = traffic + coordination
you don’t fix traffic by buying a faster engine.
you fix it by:
- better routing
- fewer stops
- fewer unnecessary loops
instead of thinking: “do i need more compute?” think: “why is my system doing so much work?”
so this isn’t a hardware problem for builders. it’s a design problem.
the cpu bottleneck shows up as slow, expensive, and fragile workflows. the way to fix it is not by changing infrastructure, but by reducing steps, cutting retries, and making execution more efficient.
how companies are reacting
the clearest signal is that hardware vendors are redesigning around this.
nvidia, historically gpu-first, is now building cpus specifically for agent workloads. its vera cpu is positioned around data movement, scheduling, and orchestration rather than raw compute.
Across six architecture generations, NVIDIA has improved inference throughput per megawatt by about 1,000,000x, turning data centers into AI token factories that convert energy into revenue‑generating intelligence.
— NVIDIA Data Center (@NVIDIADC) March 25, 2026
NVIDIA Hopper, Blackwell, and Vera Rubin — with NVIDIA Vera CPU… pic.twitter.com/8m7GMbnZFP
intel and amd are pushing cpu-centric architectures for execution layers. arm is entering data center ai with cpus designed for agentic systems.
AI doesn't run on accelerators alone — it runs on systems 🖥️
— Intel (@intel) April 9, 2026
We're deepening our collaboration with @Google to advance AI infrastructure built for the real world: Intel Xeon CPUs powering Google Cloud + expanded co-development of custom IPUs for smarter, more efficient hyperscale… https://t.co/GkAl4F4akX
across infrastructure, the focus is shifting toward memory bandwidth, data pipelines, and system coordination, not just model performance.
the stack is moving up. the model is no longer the whole system.
what this means if you’re building
the constraint is no longer just intelligence. it’s execution.
your system performance will depend on how efficiently you:
- orchestrate multi-step workflows
- manage memory and state
- handle retries and failures
- integrate external tools and apis
the important metric is changing from cost per token to cost per completed task.
and task cost is driven heavily by cpu-side work.
takeaway
ai is hitting a familiar limit. not in theory, but in infrastructure.
when you build in digital, you are still constrained by physical systems. hardware, latency, bandwidth, coordination.
for the last phase, the constraint was gpus. for the next phase, it will increasingly be everything around them. if your product relies on agents, the question is no longer just how smart they are. it’s whether your system can actually run them.


