 Addy Crezee
Addy Crezee

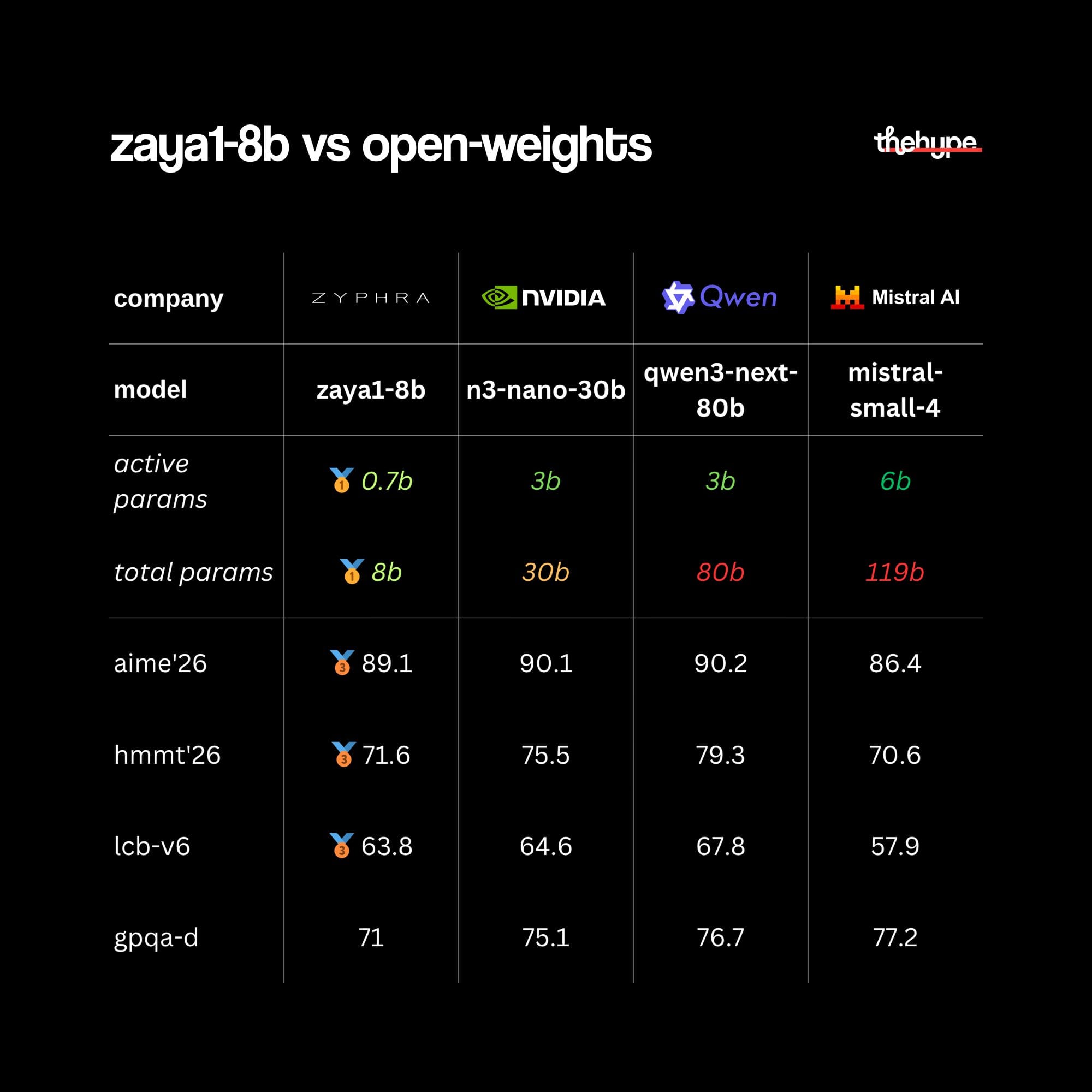
zyphra just released open weights that beat models 15x their size on math benchmarks
their new model is called zaya1-8b. mixture-of-experts, only 760m active params out of 8.4b total. apache 2.0, fully open.
the benchmarks don't make sense for something this small:
• aime '26: 89.1 – elite us math olympiad problems
• hmmt feb '26: 71.6 – harvard-mit math tournament
• imo-answerbench: 59.3 – international math olympiad level
• livecodebench-v6: 65.8 – fresh coding problems, post-training-cutoff
• gpqa-diamond: 71.0 – phd-level bio/chem/physics questions
it's beating models with 10x more active parameters on hard math
the scaling comparison is the real story
zaya1-8b (0.7b parameters active) vs mistral-small-4 (119b parameters total):
- aime: 89.1 vs 86.4
- hmmt: 71.6 vs 70.6
a model that fits on your phone winning against a 119b param model on competition math
how? a few genuine technical innovations:
• most models are pretrained on raw text, then reasoning is added in post-training via fine-tuning. zyphra included reasoning traces during pretraining itself – so the model learned to think step-by-step from the ground up, not as a patch on top
• post-training runs four sequential rounds of trial-and-error learning. the model attempts problems, gets scored on how well it did, and updates itself based on that score – no human labeling needed. first round warms up basic reasoning, second throws increasingly hard problems at it, third focuses purely on math and code, fourth polishes how it behaves and follows instructions. each round specializes the previous one instead of trying to do everything at once
• "markovian rsa" – when the model generates multiple candidate answers and picks the best one, each candidate carries a long chain of reasoning behind it. normally that eats through your context window fast. zyphra's fix: instead of keeping the full reasoning history for each candidate, only keep the last chunk. the model forgets the early scratch work but remembers where it ended up. same quality, fraction of the memory cost.
the old playbook was simple: more parameters = smarter model. throw more compute, hire more engineers, train bigger
zaya1-8b breaks that assumption. if a 65-person startup can match 119b-parameter models by being smarter about how they train, parameter count stops being a moat. architecture and training methodology are
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
— Zyphra (@ZyphraAI) May 6, 2026
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵 pic.twitter.com/URTj1br9tw


