 Nick Trenkler
Nick Trenkler

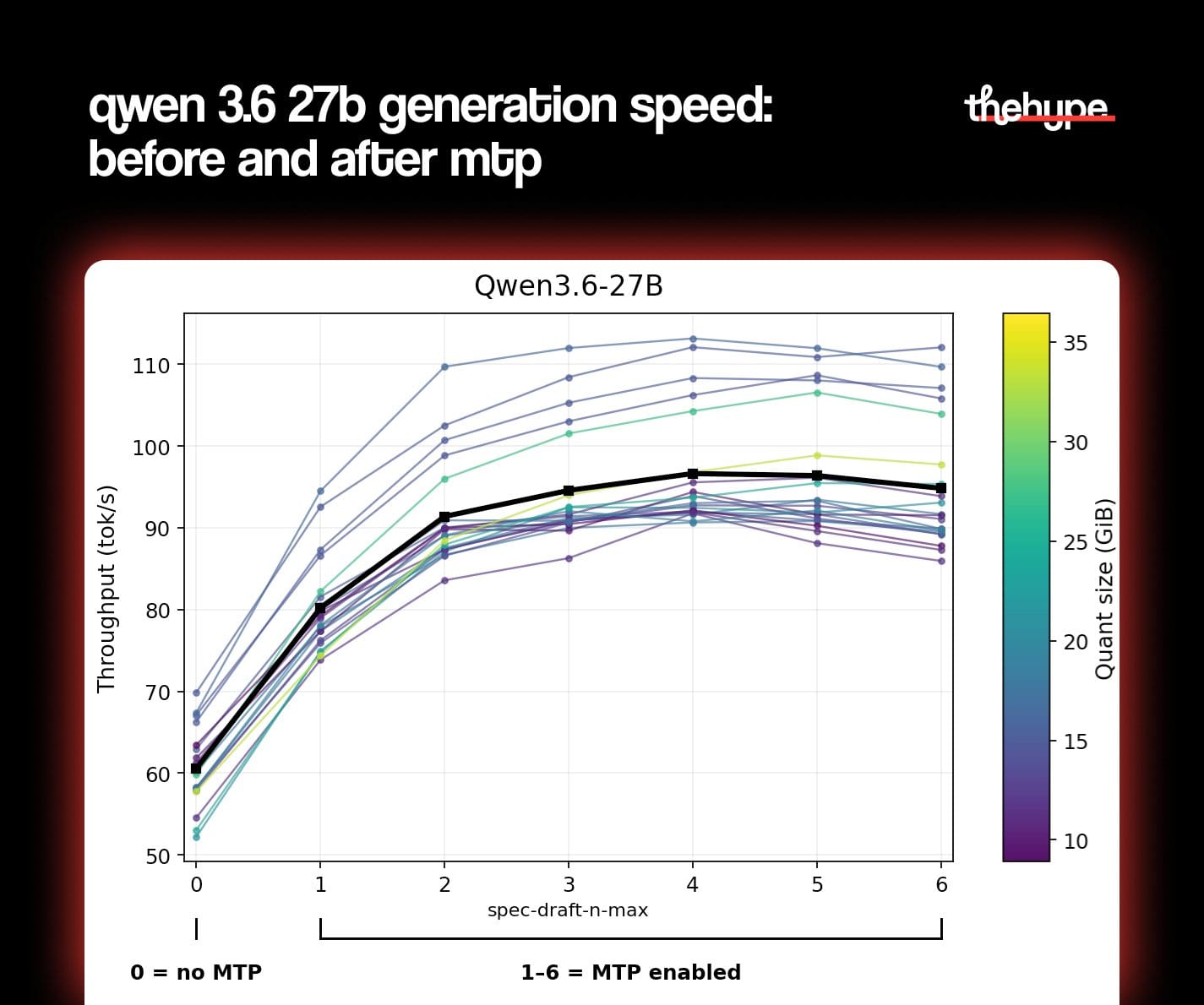
from 50–70 tok/s to 75–110 tok/s – tokens per second is basically how fast the model types back at you, one token being roughly one word. here's how they pulled it off:
1. dynamic quantization. instead of shrinking every part of the model equally, unsloth figured out which weights matter most and kept those at higher precision. the result is a Q4_K_XL file that's only 17.9gb – that's a 27 billion parameter model compressed from its original 54.7gb BF16 size, small enough to fit in a single consumer gpu with 18gb vram
2. multi-token prediction (mtp). normally a model predicts one token at a time. with mtp, qwen 3.6 was trained to draft multiple tokens ahead simultaneously, and llama.cpp just merged official support for this on may 16th. unsloth was ready day one
those two things together – a model small enough to fit in vram, running with speculative decoding baked in – is why you're getting near 2x throughput without touching model quality
models are being compressed by both the open-source community and major providers – and the pace is accelerating. the end goal is clear: llms small enough to run on a consumer laptop or smartphone, no api calls, no cloud dependency, just local inference baked directly into any app
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
— Unsloth AI (@UnslothAI) May 18, 2026
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: https://t.co/7gWhKnseZo
Guide: https://t.co/7qzk6ypWDQ pic.twitter.com/8ICXw7iV3G


