 Nick Trenkler
Nick Trenkler

cursor just released composer 2.5, their most powerful model yet. it's faster, smarter on long tasks, and better at following complex instructions. the wild part? it's built on kimi k2.5 – open-source, released by moonshot ai on january 27, 2026
they didn't just fine-tune it though. they scaled training, created harder practice environments for reinforcement learning (a technique where the model learns by trial and error – rewarded for good outputs, penalized for bad ones), and used text feedback so the model could look back at a long coding session and understand which of its own decisions actually mattered
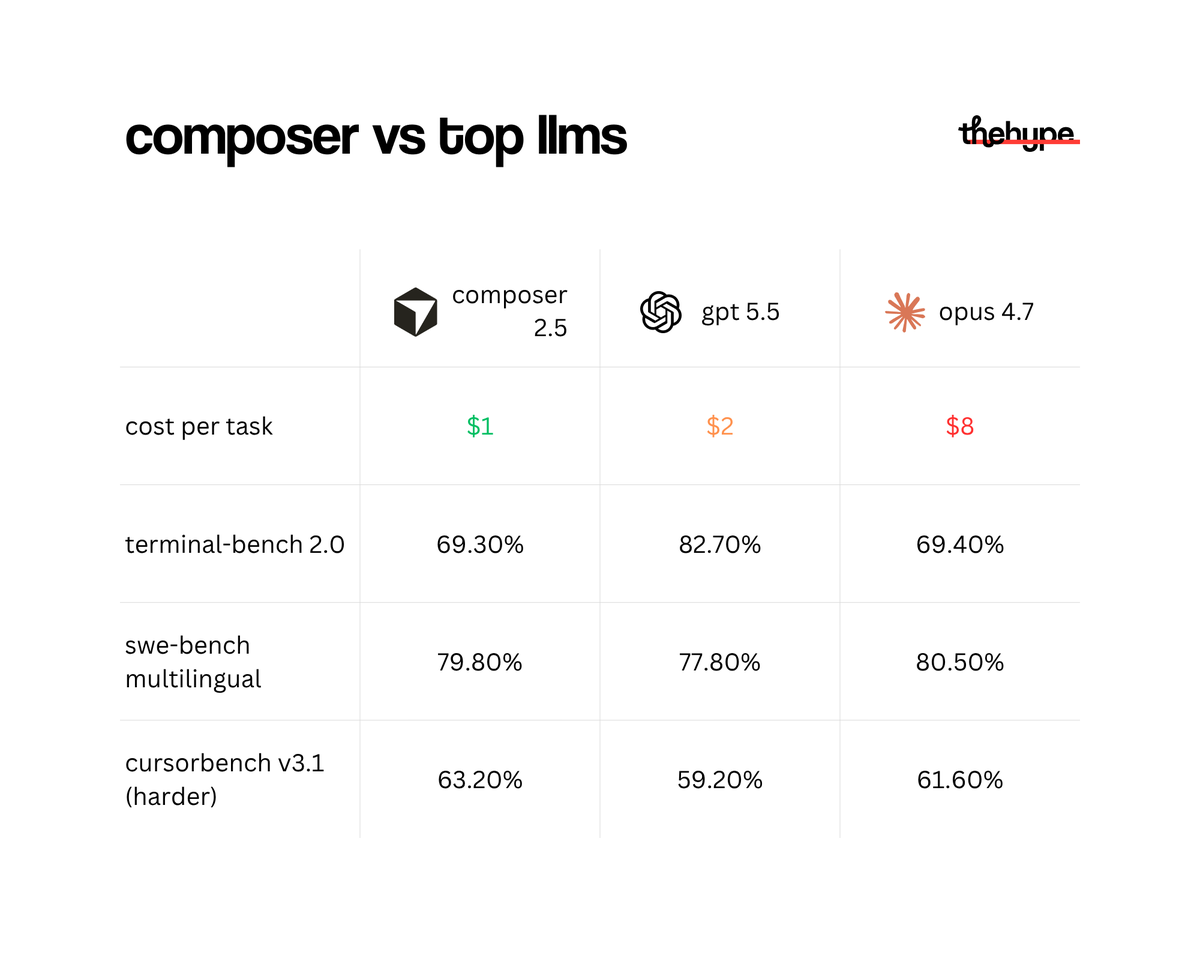
the result is a model that's up to 10x more efficient than similarly capable models. and the cost reflects that: composer 2.5 sits near $1 per task on cursorbench v3.1, while opus 4.7 at its default setting costs around $8 per task for a lower score. gpt-5.5 at default lands around $2 but still scores below composer 2.5
and it holds its own against the big names:
• terminal-bench 2.0: 69.3% – nearly tied with opus 4.7 (69.4%)
• swe-bench multilingual: 79.8% – just behind opus 4.7 (80.5%), but beats gpt-5.5 (77.8%)
• cursorbench v3.1 harder tasks: 63.2% – competitive with gpt-5.5's default config (59.2%) and opus 4.7's default (61.6%)
an open-source chinese foundation model, meaningfully improved by a coding startup, competing with frontier labs' flagship releases
the moat isn't the base model anymore. it's what you build on top of it
Introducing Composer 2.5, our most powerful model yet.
— Cursor (@cursor_ai) May 18, 2026
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model. pic.twitter.com/N87ojcXlOC


