 Julia Daimio
Julia Daimio

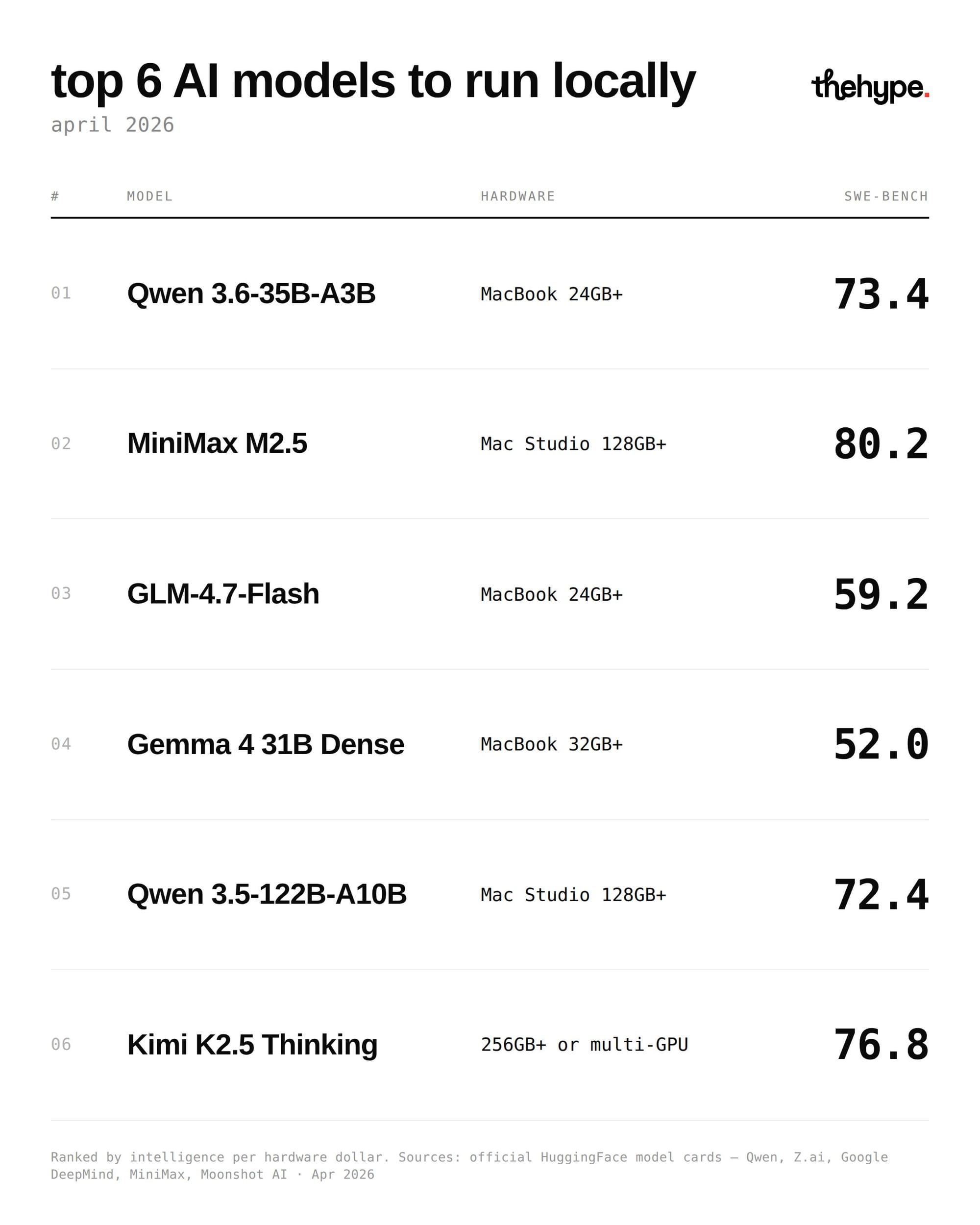
if you want to run strong models without living inside the cloud bill, april 2026 looks pretty fun:
1. qwen 3.6-35b (@Alibaba_Qwen) – 73.4 swe-bench on a 24gb macbook. best intelligence per dollar rn
2. minimax m2.5 (@MiniMax_AI) – 80.2 swe-bench (ceiling here), but needs mac studio tier hardware
3. glm-4.7-flash (@Zai_org) – 59.2 swe-bench, but strong tool-calling + reliable today
4. gemma 4 31b (@GoogleDeepMind) – not about coding, but top-tier for reasoning workflows
5. qwen 3.5-122b (@Alibaba_Qwen) – 72.4 swe-bench + strong tool use, same tier as minimax
6. kimi k2.5 thinking (@Kimi_Moonshot) – 76.8 swe-bench, but needs 256gb+/multi-gpu
how we ranked:
not “best model overall” – but best for your hardware
- macbook (24–32gb)
- mac studio (128gb+)
- multi-gpu / enthusiast
we used swe-bench verified as the main signal. not benchmarks for toys or exams.
which one are you running?
⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
— Qwen (@Alibaba_Qwen) April 16, 2026
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking + non-thinking modes… pic.twitter.com/UMiChPaLid


