 Nick Trenkler
Nick Trenkler

ai models are evolving in two directions right now
- direction 1: raw capability. push benchmarks, scale compute, chase agi. examples: openai, anthropic, google
- direction 2: efficiency. match frontier performance while cutting costs and parameters. ernie 5.1 by baidu is a good case study here
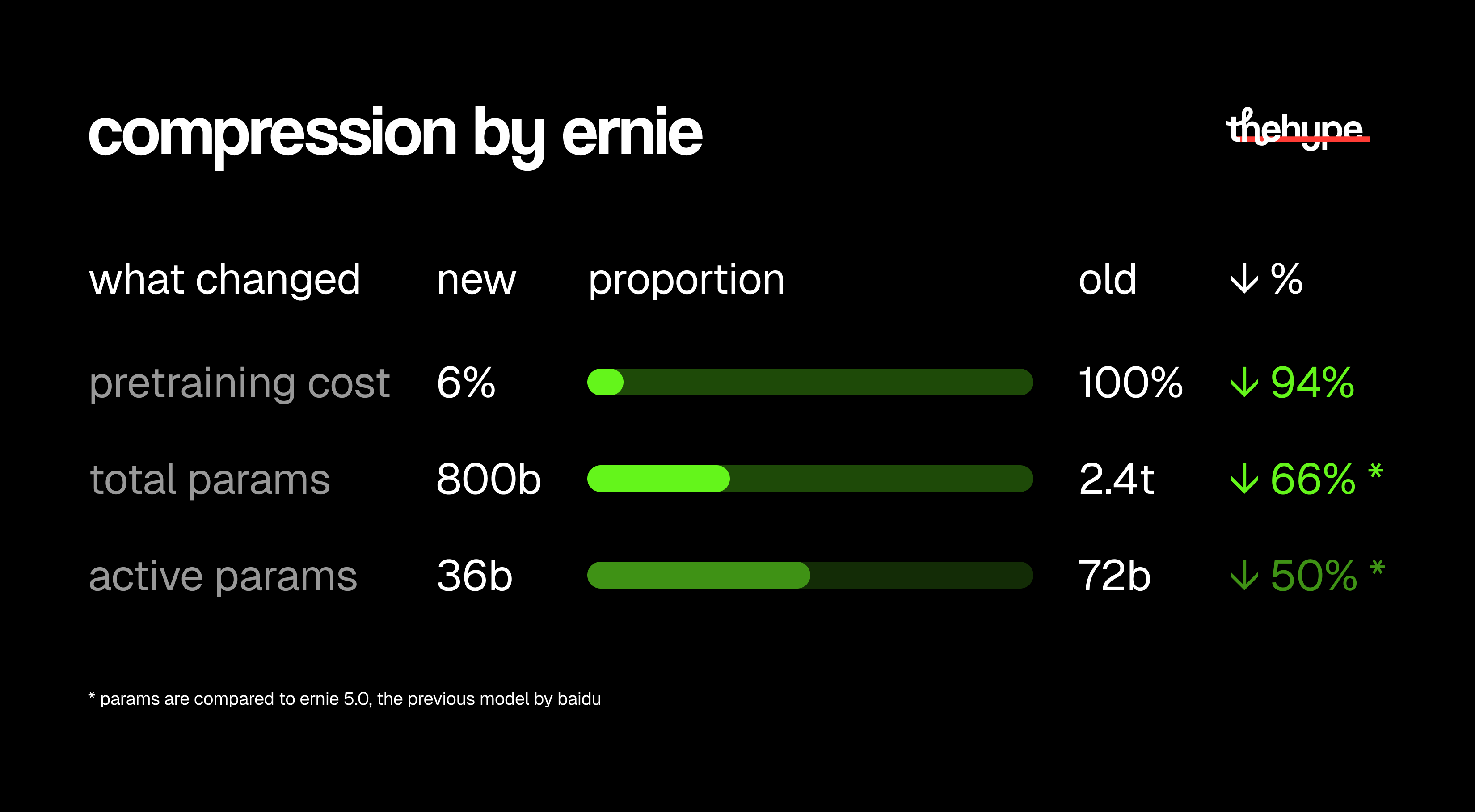
compared to ernie 5.0, the new model is significantly smaller:
• 800b total params vs 2.4t (↓66%)
• 36b active params vs 72b (↓50%)
and compared to models at the same capability level, pretraining cost is 94% lower.
benchmark results vs claude opus 4.6 and gemini 3.1 pro:
• aime26 w/tools (math olympiad problems): 99.6 vs 81.2 and 99.9
• deepsearchqa (multi-step web research questions): 77.3 vs 82.0 and 79.3
• mmlu-pro (broad academic knowledge across 14 subjects): 84.3 vs 89.5 and 87.7
• advance-if (following complex, layered instructions): 72.3 vs 73.4 and 83.9
the gap between frontier and frontier-efficient is narrowing. that's worth paying attention to
ERNIE 5.1 is here 🚀
— ERNIE for Developers (@ErnieforDevs) May 9, 2026
ERNIE 5.1 significantly reduces pretraining cost while compressing total parameters to ~1/3 and activated parameters to ~1/2 — using only ~6% of the pretraining cost compared to models at similar scale, while achieving leading performance in its class.… pic.twitter.com/jyjFx5bSG7


