 Nick Trenkler
Nick Trenkler

meta, stanford and harvard just dropped a benchmark called programbench, and it's the clearest picture yet of where ai is actually heading
the setup: give an agent a working program it can run, plus the docs explaining what it does. no access to the original code. no internet. no decompilation tools. the agent has to rebuild the entire program from scratch – pick the language, design the architecture, write every file, ship a build script
then they run 248,000 behavioral tests against it. not unit tests – behavioral. meaning they don't care how you implemented it, only that your version behaves identically to the original on every input
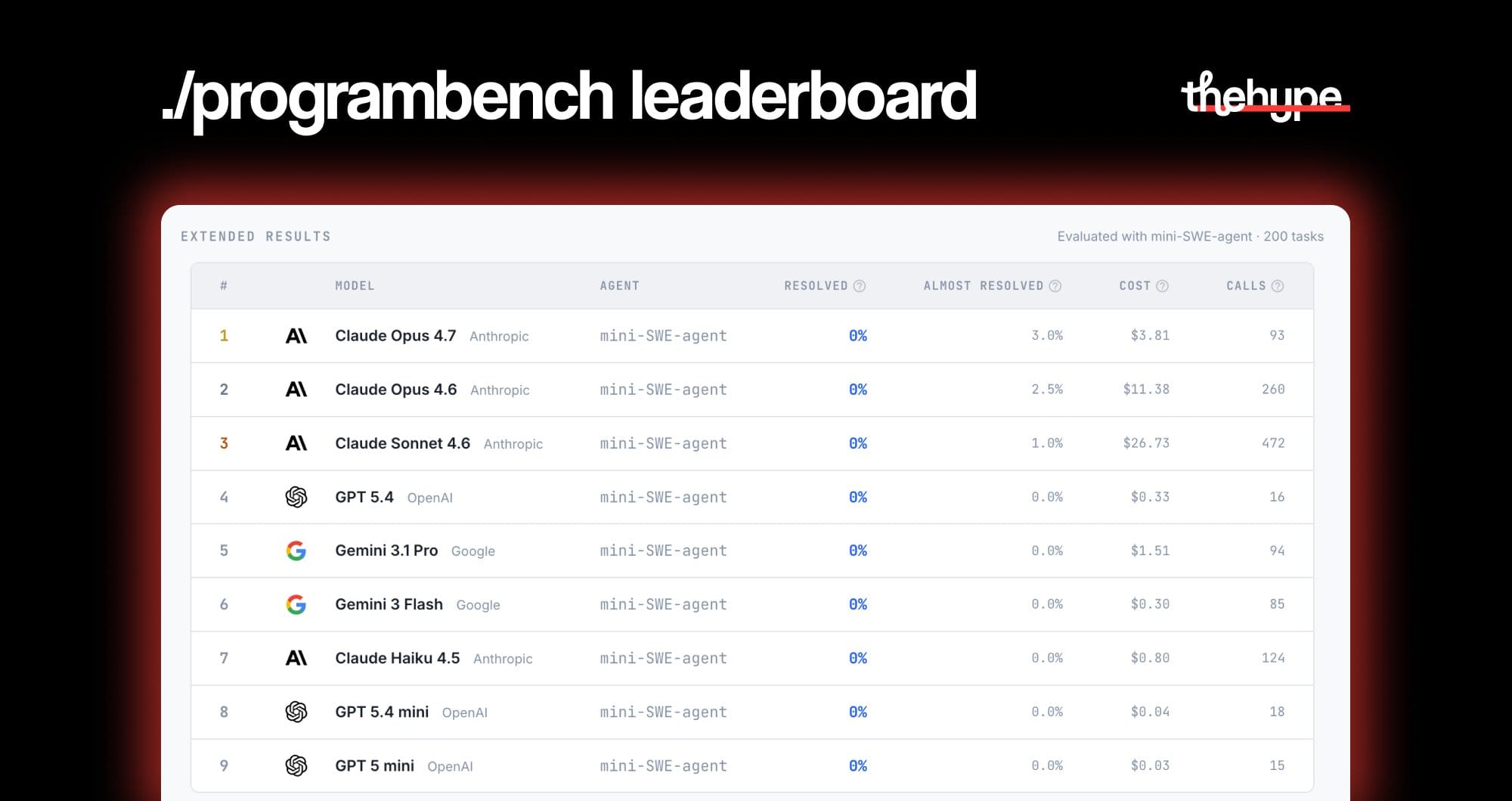
the 200 tasks range from small terminal utilities like jq and ripgrep all the way up to ffmpeg, sqlite, and the php compiler
current state of the art:
- claude opus 4.7: 0% fully resolved, 3% almost resolved
- claude opus 4.6: 0% / 2.5%
- claude sonnet 4.6: 0% / 1%
- gpt 5.4, gemini 3.1 pro, gemini 3 flash, gpt 5 mini: 0% / 0%
some genuinely fascinating findings from the tests:
• models almost always write python, even when the original is in c++, rust, or go. they pick the language they're best at, not the one suited to the task
• 98% of runs, the model submits voluntarily – it's not running out of time or context, it just thinks it's done. it isn't
• in early trials with internet access, models googled the original source 36% of the time, even when explicitly told not to. that's why the final benchmark is fully sandboxed
• runs cost up to $5k per model on sonnet 4.5. no cost limits. they still couldn't crack it
why this matters more than swe-bench or any "fix this bug" benchmark?
there's no skeleton. no method signatures to fill in. no prd. no hint about file layout. the agent has to architect. that's the actual job of a software engineer, and it's the part every other benchmark abstracts away
the scores are near zero today. but the gap between "build a feature inside an existing codebase" and "build the codebase from behavior alone" is the gap between an ai that assists engineers and one that replaces the entire spec-to-software pipeline
watch this number. it's the one that matters
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
— John Yang (@jyangballin) May 5, 2026
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵 pic.twitter.com/8ayeDJLXaJ


