 Nick Trenkler
Nick Trenkler

the original opus 4 shipped eleven months ago. it already feels obsolete. opus 4.7 is +26 points on terminal coding, +15 on agentic coding, +11 on reasoning. the models aren’t just getting better – the gap between “last year’s frontier” and “this week’s frontier” is starting to look embarrassing.
release rhythm tells story first
with the 2025–2026 releases, opus stopped looking like a slow-moving flagship and started behaving like a living product line: shipping in tighter intervals, getting better at agentic work faster than at classic “reasoning,” and expanding from coding into a broader knowledge-work model.
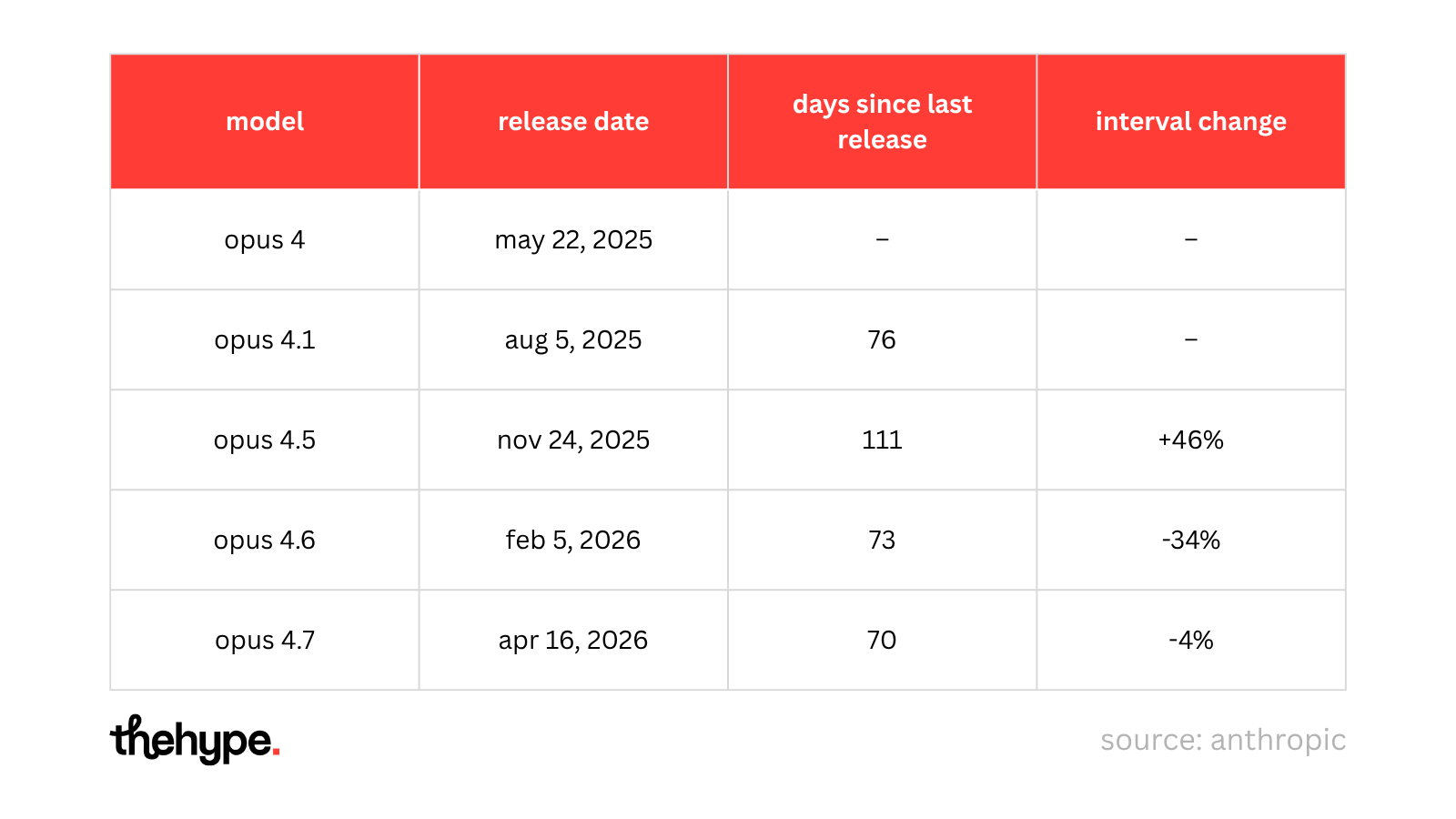
opus 4 launched on may 22, 2025. opus 4.1 followed 76 days later. then 4.5 came after 111 days, 4.6 after 73 days, and now opus 4.7 lands just 70 days later on april 16, 2026.
it’s a ~10-week release loop. opus is being shipped like software.
from model to product line
- opus 4 was introduced as the “best coding model,” built around swe-bench, terminal tasks, and long-running agents with early memory capabilities.
- opus 4.1 was a classic point release: same positioning, tighter execution – better real-world coding, better agentic search.
- opus 4.5 was the pivot. opus stopped being just a coding/reasoning system and became a work model: research, spreadsheets, slides, browser tasks, long workflows.
- opus 4.6 expanded that with 1m context, adaptive thinking, agent teams, and stronger performance on finance/legal tasks.
- opus 4.7 doesn’t change direction – it stabilizes it. better instruction following, self-verification, higher reliability on long tasks. less supervision needed.
benchmarks tell a different story than you’d expect
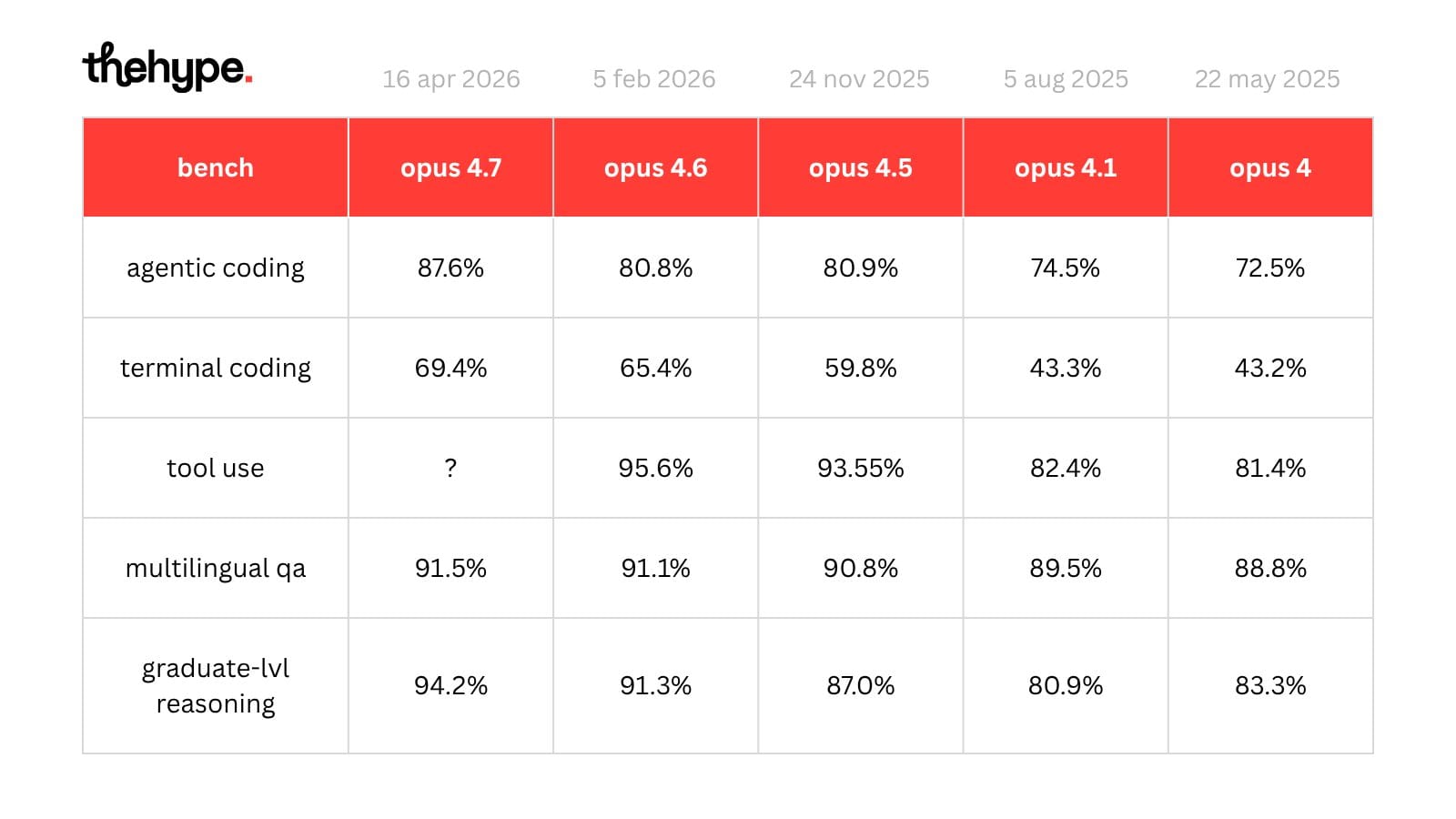
from opus 4 to opus 4.7, the biggest gains were not in classic reasoning, but in agentic and operational tasks:
- terminal coding: 43.2% → 69.4%
- agentic coding: 72.5% → 87.6%
- multilingual qa: 88.8% → 91.5%
- graduate-level reasoning: 83.3% → 94.2%
("tool use" isn’t published for 4.7, but previous jumps suggest the same direction.)
what changed is not just the numbers – it’s the gap between them.
agentic and terminal tasks saw the steepest acceleration, while multilingual qa barely moved. reasoning improved meaningfully, but not disproportionately.
the takeaway stays the same, just stronger:
the frontier is no longer “can the model answer harder questions.”
it’s “can it keep working inside messy environments over long periods of time.”
anthropic’s real win isn’t raw intelligence. it’s turning intelligence into reliable execution.
positioning shifted with the capabilities
you can see the transition in how each version was framed:
- opus 4: best coding model
- opus 4.1: better coding precision
- opus 4.5: coding + research + office work
- opus 4.6: coding + long-context + economic tasks
- opus 4.7: reliable execution on complex work
each step moves further away from benchmarks and closer to workflows. opus improved by becoming less benchmark-theatrical and more workflow-native.
what actually changed
the gap between opus 4 and opus 4.7 isn’t just higher scores.
it’s a structural shift across three layers:
- faster release cadence
- biggest gains in agentic / operational tasks
- broader lifecycle: from elite coder → general-purpose work engine
that’s why the story isn’t “anthropic improved opus.” it’s that opus is no longer a single model. it’s becoming a continuously updated operating layer for work.


