 Nick Trenkler
Nick Trenkler

minimax just open-sourced m2.7 – but the real story isn’t the model. it’s the 3.5-week delay.
thehype looked at why that delay actually matters.
model performance
first, the model itself: it’s strong. m2.7 scores around 56% on swe-bench (fixing real-world coding bugs) and 57% on terminal bench (completing agent-style tasks). in simple terms, it solves a bit more than half of real engineering problems end-to-end – which is already very capable.
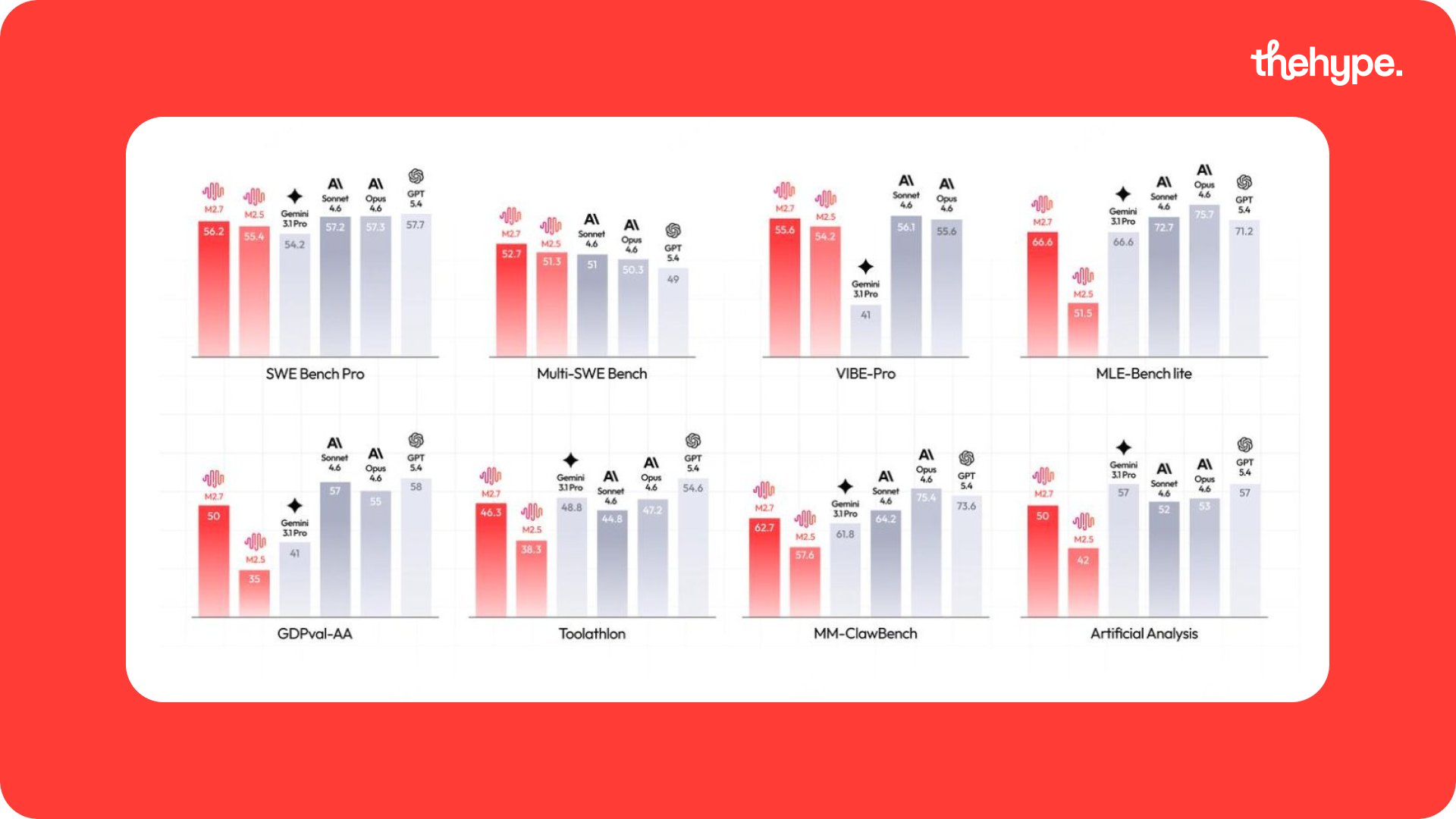
for context, top closed models tend to land in the ~60% range, while most open models sit around 45–60%. so m2.7 is right near the top tier of open-weight models.
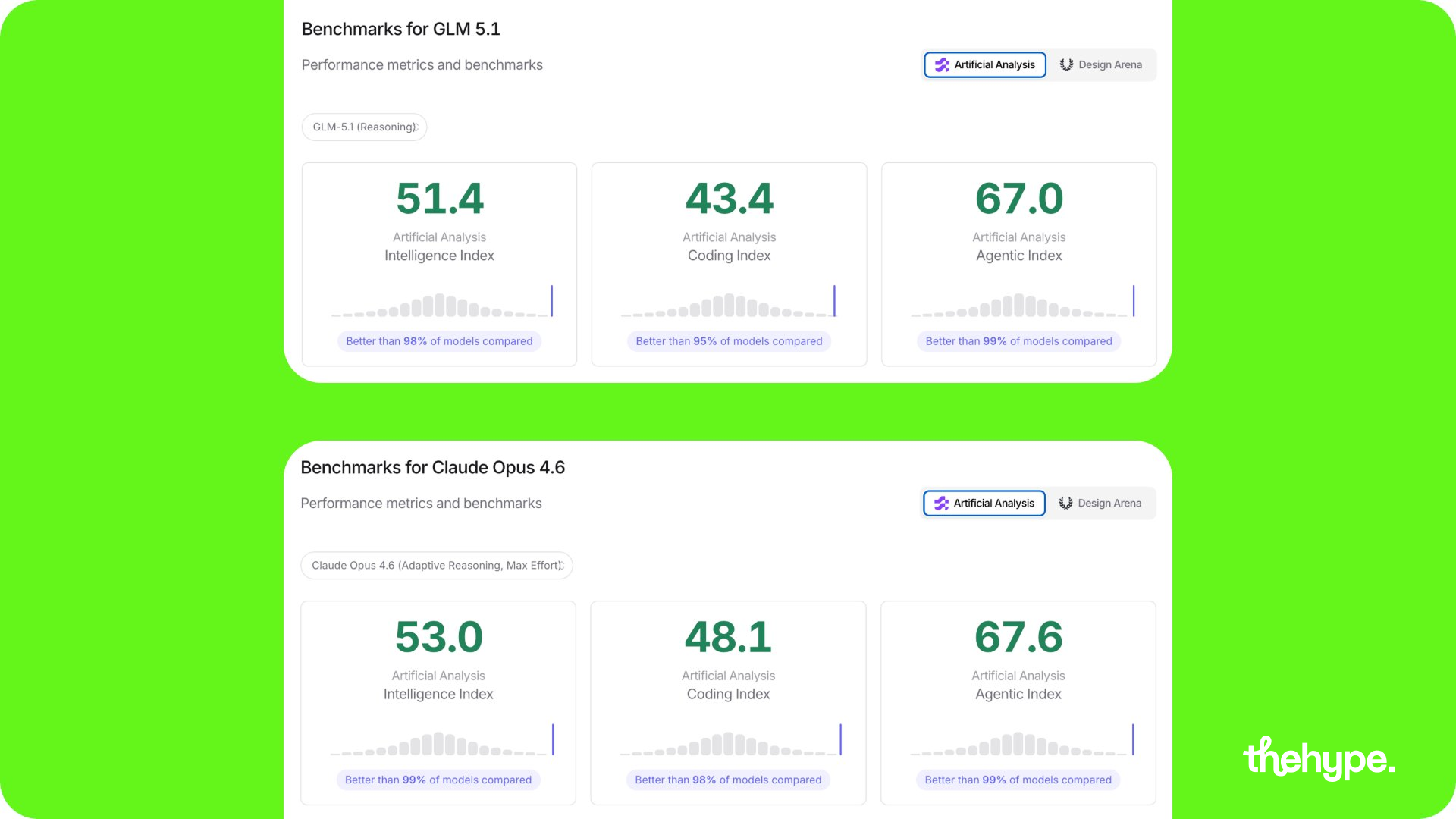
real usage
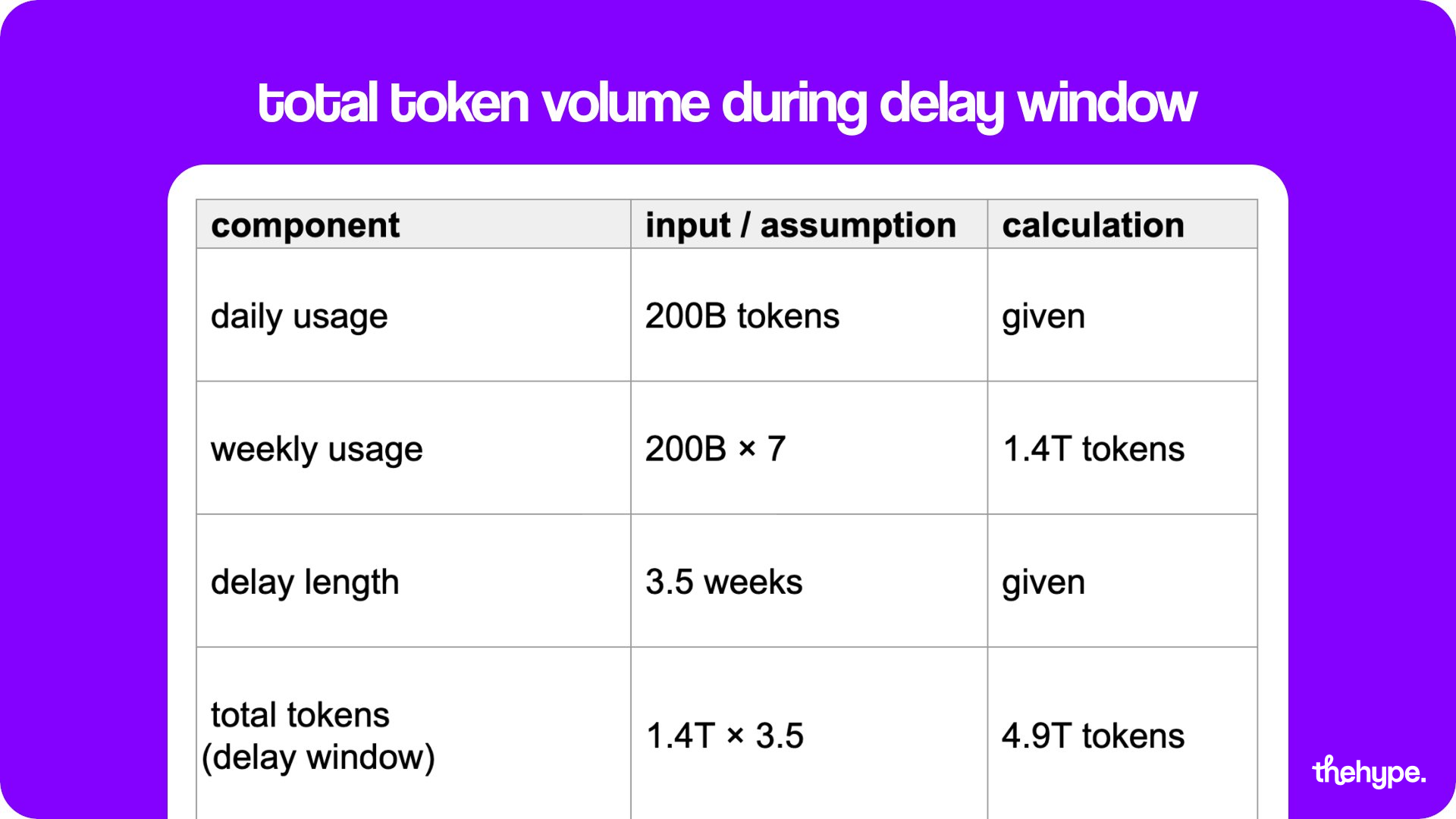
and this wasn’t a quiet release. before open-sourcing, the model was already doing around 200B tokens per day on openrouter – meaning real usage, real demand, and likely real revenue. that matters more than benchmarks, because it proves people were actually building with it.
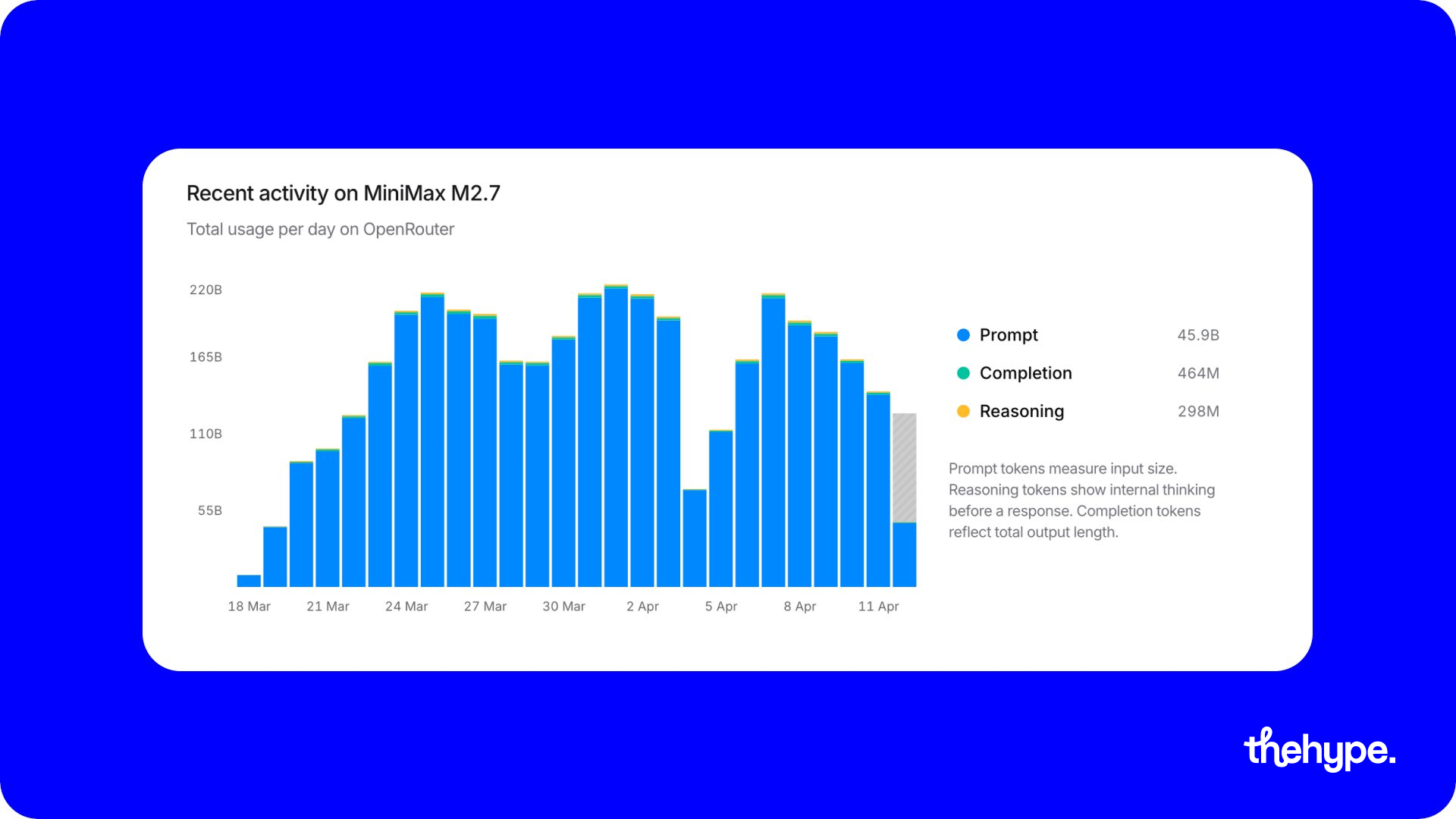
this level of usage also sets up the core tension of the next section: once a model is deeply embedded in production, every week of delay before open-sourcing has direct financial implications.
the delay
now the part most people missed: the delay.
minimax initially said open weights would come “in ~2 weeks.” then it became “this weekend.” then nothing. the eventual release landed roughly 3.5 weeks late, along with an apology to developers.
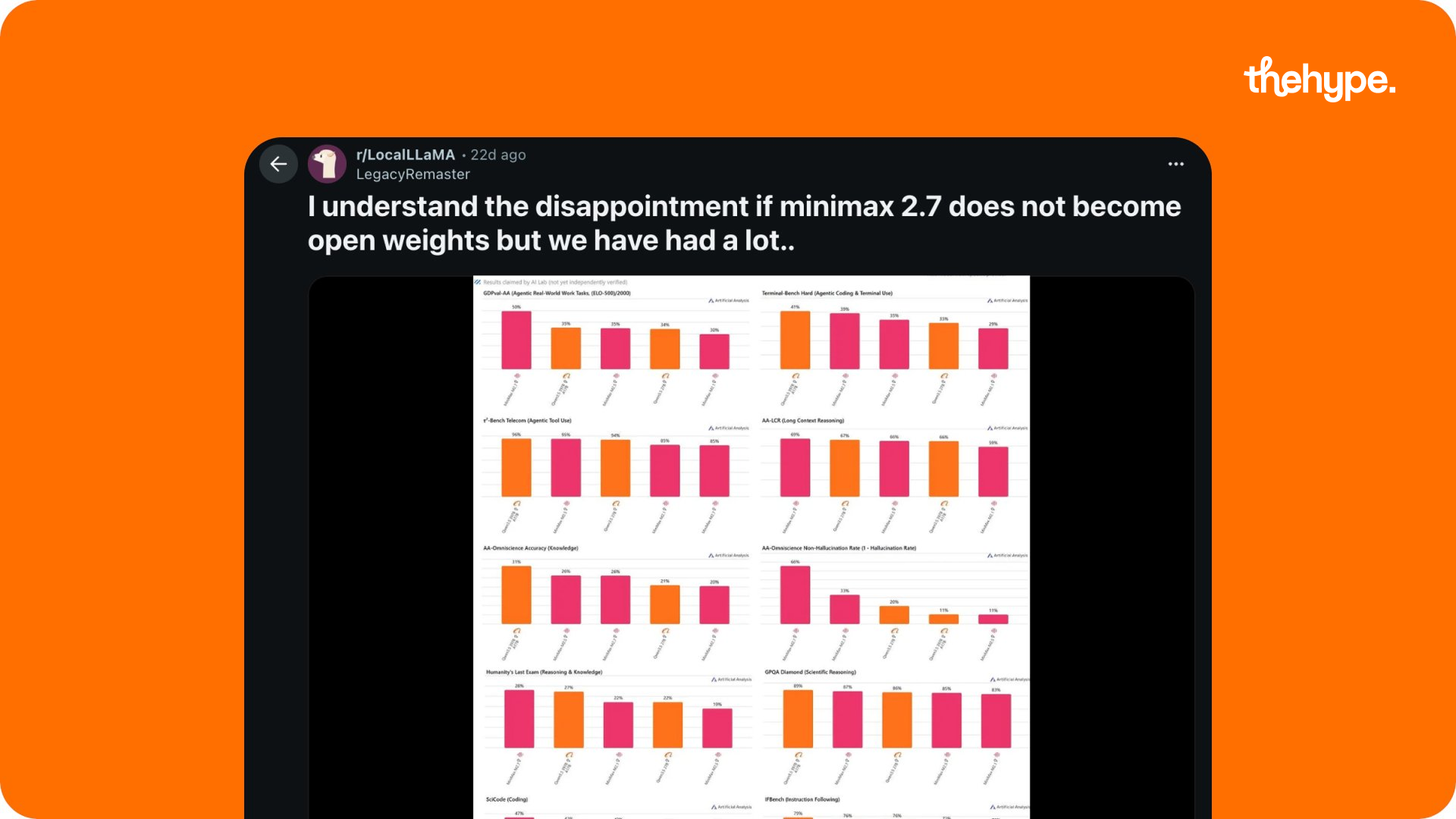
that gap is where the real story starts.
why the delay matters
that changes the framing.
this isn’t just “another open model.” it’s “a high-demand model was kept closed first, then opened later.”
and that shift only matters because of what was happening earlier: massive real-world usage. if there were no users, delay wouldn’t matter. but at scale, even small delays become meaningful revenue windows.
economic incentive
so why delay? because open weights fundamentally break the economics of an api-first ai company.
once weights are public:
- users can self-host instead of paying for the api
- enterprises gain leverage in pricing negotiations
- competitors and infra providers can undercut you
- margins compress toward raw compute costs
in other words, control over distribution disappears.
and that connects directly back to the usage scale: the more demand already exists, the more valuable each additional api-only week becomes.
that creates a clear incentive: a timing window.
launch the model, monetize via api, then release weights later.
for a top-tier model, that window might only last 4-12 weeks before something better comes along. releasing weights immediately removes that window. delaying preserves it.
minimax may have just demonstrated that approach in real time.
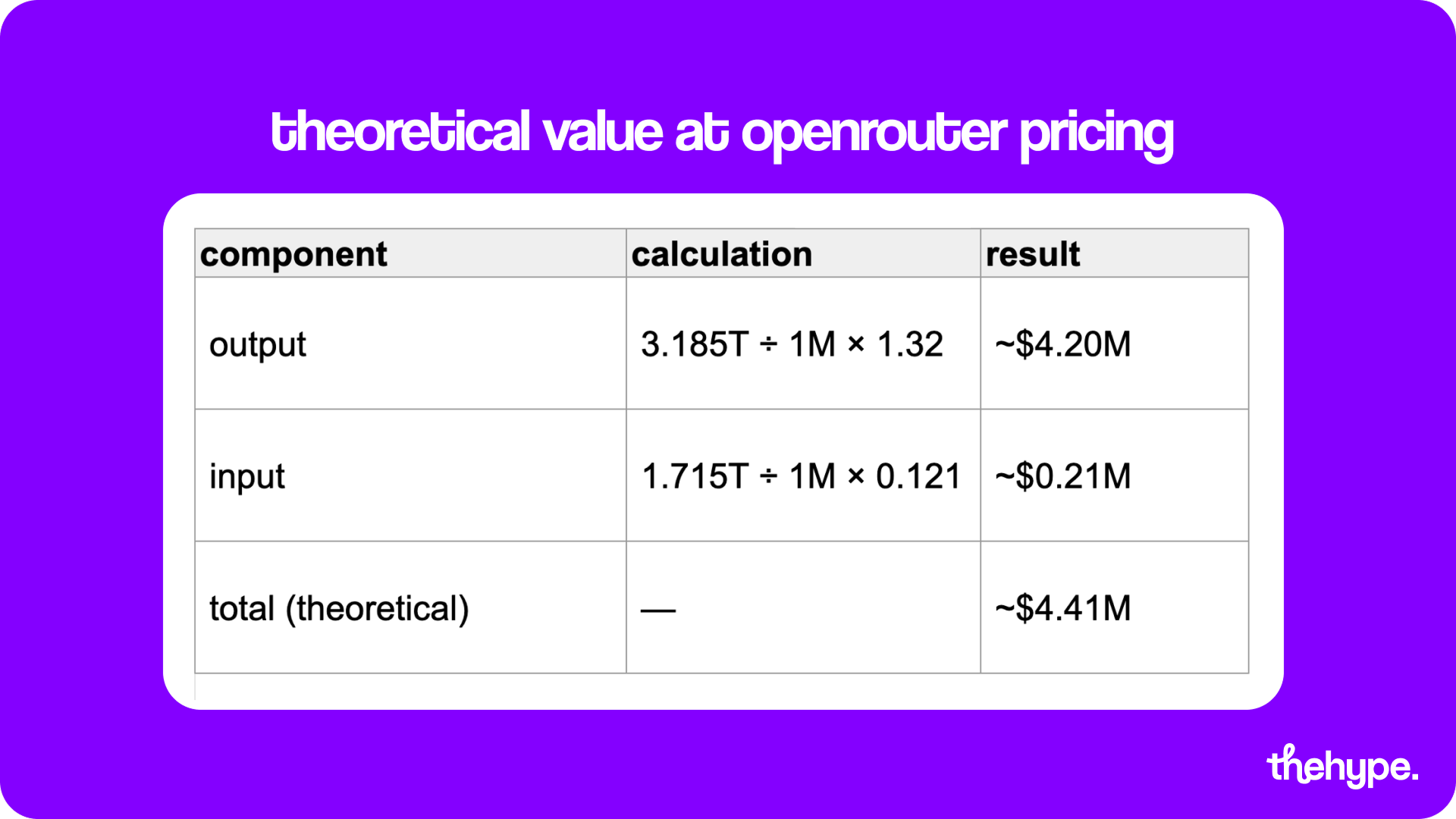
we estimated how much minimax could have captured during the delay window using real effective pricing (openrouter) and reported usage scale.

company differences
there’s an important nuance here, though: this dynamic does not apply to every lab.
companies like deepseek are backed by hedge fund capital. they do not rely on direct model revenue in the same way, so open-sourcing can help with reach, hiring, and influence. there is less incentive to delay.
similarly, alibaba, through models like qwen, monetizes cloud infrastructure. open models bring developers into their ecosystem, which increases compute usage. for them, early release can actually be beneficial.
minimax is structurally different. publicly traded on hkex since january, it makes ~73% of revenue from consumer apps (talkie, hailuo ai) and the rest from its open platform api. in both cases the model is the moat — releasing weights lets competitors clone the intelligence layer underneath the apps while enterprises self-host instead of paying for inference.
bigger signal
so this is not just a story about one model release.
it is a signal that open-source ai is entering its commercial phase, where timing becomes strategic alongside capability.
and minimax may be one of the first companies to feel that pressure so visibly, with the delay itself reflecting the trade-offs.


