 Nick Trenkler
Nick Trenkler

- top-1 on artificial analysis intelligence index, above opus 4.7, gemini 3.1, and gpt-5.4
- beats opus 4.7 on almost every benchmark. one exception: swe-bench pro (57.7% vs opus 4.7's 64.3%)
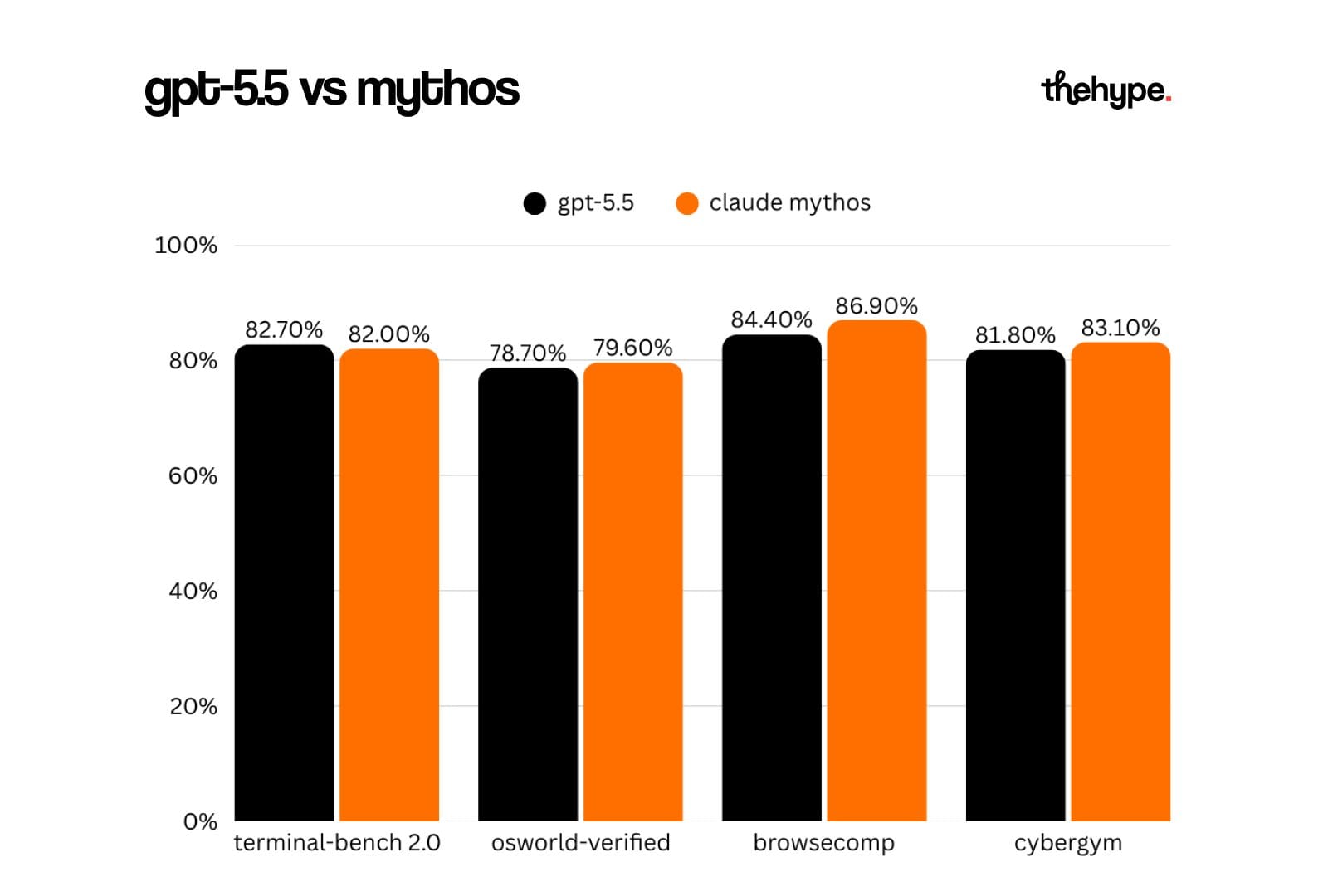
- edges out mythos on terminal bench 2.0 by 0.7pp
- completed a uk aisi cyber attack simulation end-to-end: 32 steps, ~20 hours for a human expert. but only 1 out of 10 attempts. mythos: 3/10 on the same sim.
strong as mythos, public as gpt
Introducing GPT-5.5
— OpenAI (@OpenAI) April 23, 2026
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex. pic.twitter.com/rPLTk99ZH5


