 Nick Trenkler
Nick Trenkler

first benchmark for coding agents just dropped by @artificialanlys – finally
we've been benchmarking ai models for years. but if you're actually building with ai, you're not just picking a model – you're picking a model and an agent harness (cursor cli, claude code, codex, gemini cli – these are all harnesses)
same model, different harness = completely different behavior. and until now nobody was measuring that combination properly!
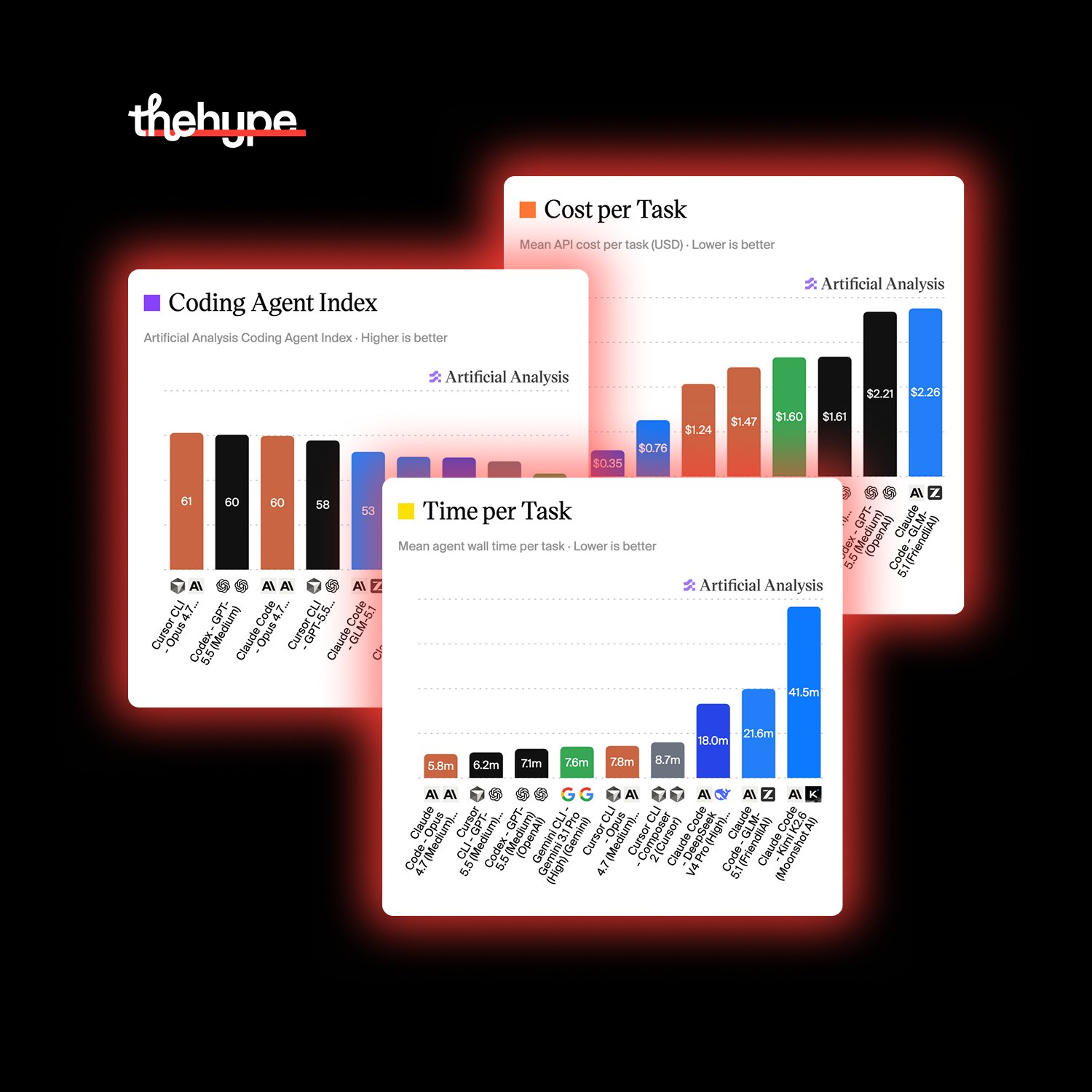
artificial analysis just launched the coding agent index, and it's the first serious attempt to benchmark model + harness combinations end-to-end on real coding tasks
the results are wild:
top performer: cursor cli + opus 4.7 at 61, edging out gpt-5.5 in codex and claude code + opus 4.7, both at 60. the gap between first and third is basically nothing – this thing is a three-way race at the top.
but the more interesting story is everything else the index reveals:
• cost per task varies 30x. from $0.07 (cursor composer 2) to $2.26 (claude code + glm-5.1). same benchmark, wildly different bills.
• time per task varies 7x. opus 4.7 in claude code finishes in ~6 minutes. kimi k2.6 takes ~40. that's not a rounding error, that's a different product category.
• gemini cli is a problem for google. gemini 3.1 pro scores 43 on this index while sitting much higher on the general intelligence index. the model is fine. the harness is dragging it down.
• cursor's composer 2 is the sleeper hit. cheapest combination tested at $0.07/task, scores 48, and it's apparently built on a post-trained kimi k2.5. cursor quietly did serious work here.
we should have had this benchmark a year ago. better late than never
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
— Artificial Analysis (@ArtificialAnlys) May 11, 2026
When developers use AI to code they’re choosing a model, but also pairing it… pic.twitter.com/W6teTy3C0N


