 Addy Crezee
Addy Crezee

сlaude opus 4.7 is live!
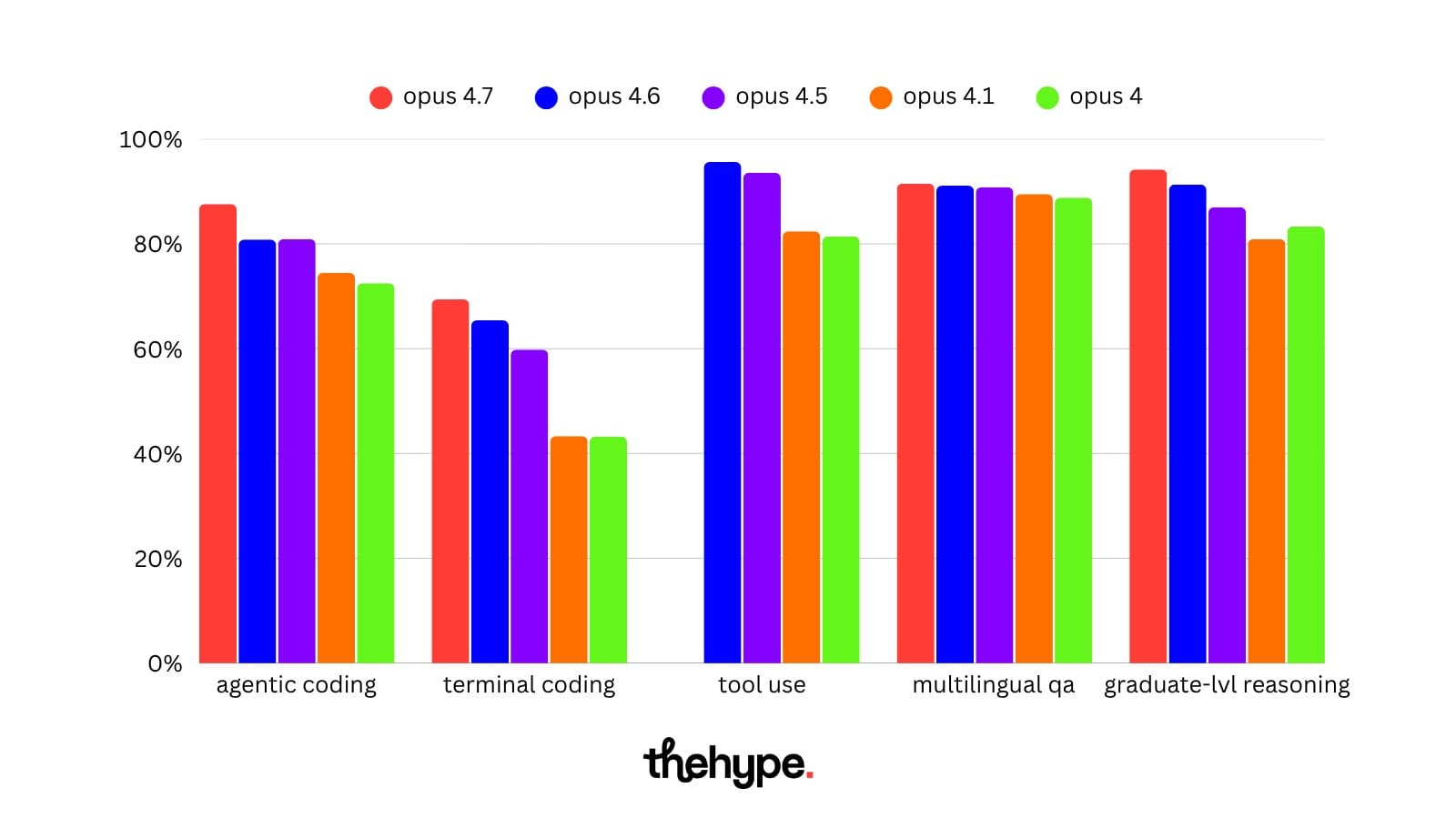
numbers that matter (4.7 vs. 4.6):
- agentic coding: 87.6 vs 80.8%
- terminal coding: 69.4 vs 65.4%
- tool use: - vs. 95.6%
- scaled tool use: 77.3 vs 75.8%
- multilingual qa: 91.5% vs 91.1%
- graduate-lvl reasoning: 94.2% vs 91.3%
Introducing Claude Opus 4.7, our most capable Opus model yet.
— Claude (@claudeai) April 16, 2026
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision. pic.twitter.com/PtlRdpQcG5


