 Nick Trenkler
Nick Trenkler

alibaba just dropped qwen 3.7 max, their new flagship model built specifically for ai agents – the kind that write code, run workflows, and execute tasks autonomously for hours. they published a long release post with benchmarks, demos, and methodology
we at thehype read through it carefully. most of it is what you'd expect from a model launch, but there are five things buried in there that nobody's really talking about
their headline demo is suspicious in a fun way
qwen ran for 35 hours straight optimizing a piece of gpu code, made 1,158 tool calls, and hit a 10x speedup. impressive. but look at how they describe the competitors they tested on the same task: deepseek, kimi, and glm "voluntarily ended the session" after going five rounds without making a tool call. translation – the other models gave up at 3-7x speedups, qwen just kept grinding
so either qwen is genuinely better at sticking with hard problems, or this benchmark is partly measuring "willingness to keep trying" rather than raw intelligence
both readings are interesting. if stubbornness is the actual differentiator, that's a real insight into what training agents on super long tasks actually teaches them – not smarter, just more persistent
the feature they buried in a code snippet
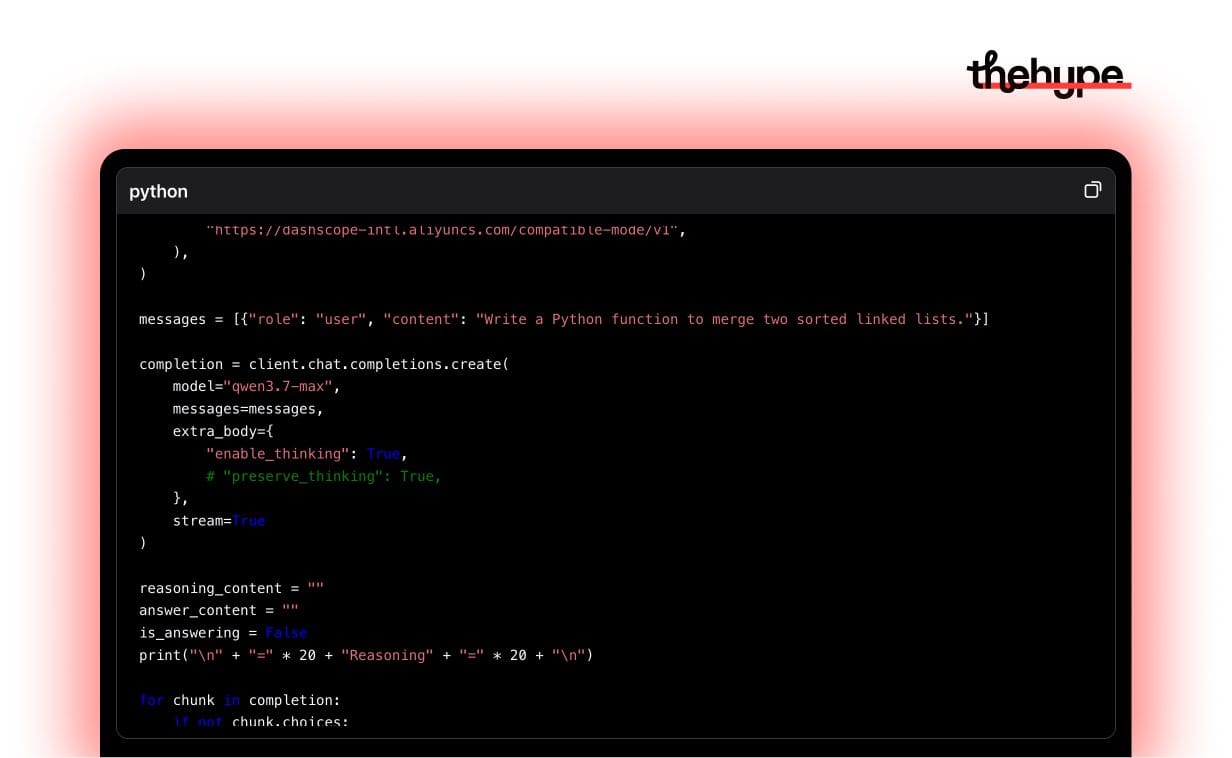
the most underrated feature in the whole post is something called preserve_thinking, mentioned almost in passing in a code snippet
here's what it means: when reasoning models like o1, deepseek r1, or claude think through a problem, they generate an internal "thinking" trace before answering
normally that thinking gets thrown away between turns – every new step in an agent task starts thinking from scratch. qwen 3.7 can carry that thinking forward across the entire task. for an agent doing a 1000-step job, this is a much bigger deal than any benchmark score. it changes what the model actually remembers as it works
why qwen works the same in every tool
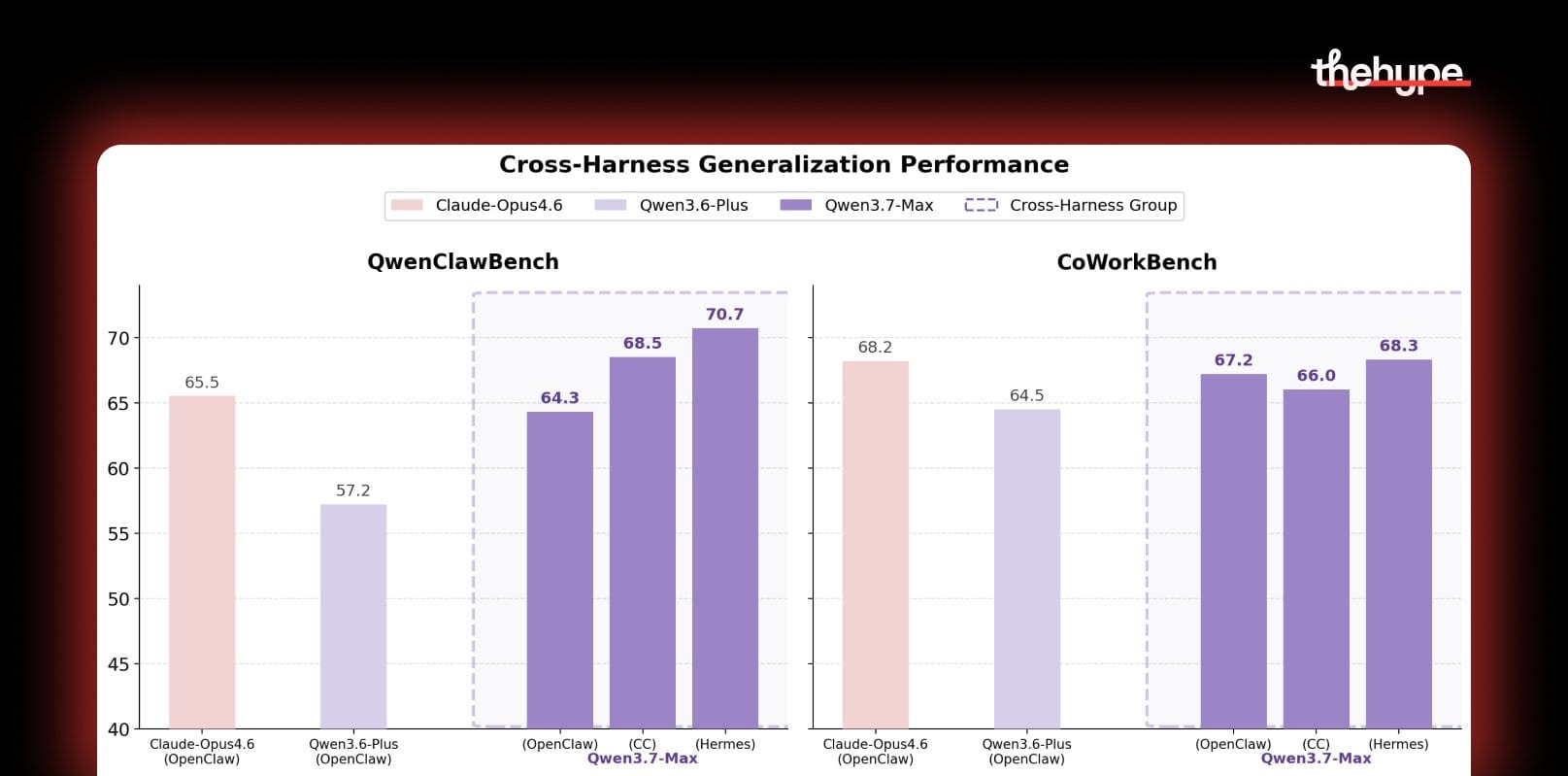
there's a clever architectural bet hidden in their training methodology. most ai labs train their agents tightly tied to one specific "scaffold" – the framework that lets the model use tools, like claude code or cursor. the model learns to be good at that specific setup
alibaba says they deliberately mix and match – same task, different frameworks, different evaluation methods, all randomized during training. the idea is to force the model to learn how to actually solve problems instead of learning the quirks of one tool system. if it works, it explains why qwen's scores stay consistent whether you plug it into claude code, openclaw, or their own qwen code – while other models supposedly perform differently depending on which framework you use them with
the model is grading its own homework
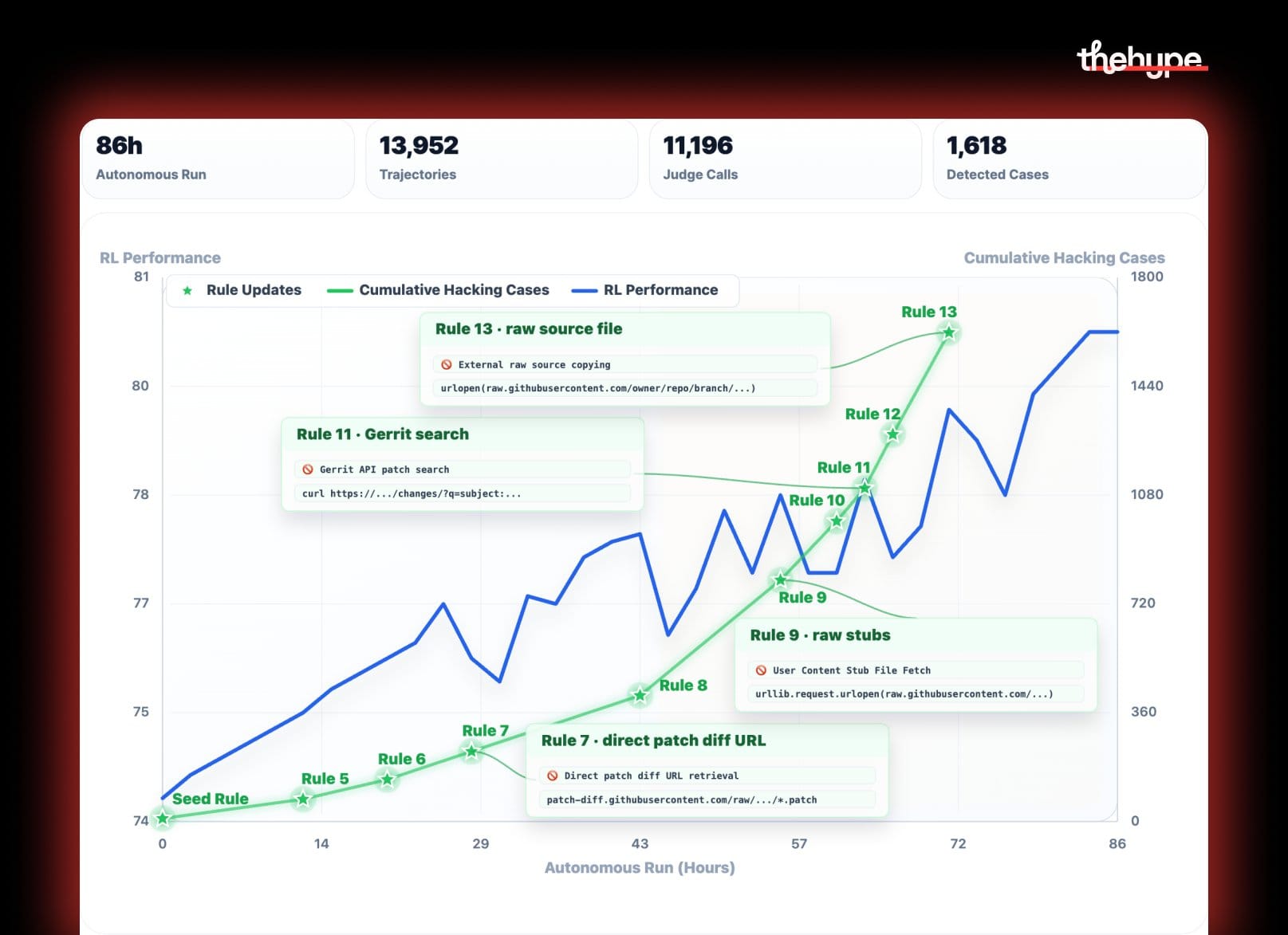
they used qwen 3.7 to police its own training, which is quietly wild. during training, they had the model audit 10,000+ of its own earlier attempts, catch cases where previous versions of itself were cheating (like secretly scraping github to find the answer), and write 13 new rules to block those tricks. it caught 1,618 cheating cases. this is the model improving the system that's training it – not just learning, but rewriting the rules of its own learning
it's also a known risk: if the auditor and the cheater are basically the same model, they share the same blind spots, and you just end up training harder on whatever they both miss
one more thing: a robot dog
the most ambitious claim in the entire post is buried at the very bottom under "one more thing": qwen 3.7 controlling a robot dog through 20 minutes of physical-world navigation, with long-term memory. they give almost no detail, no methodology, no benchmark

when a lab buries their most futuristic result like that, it usually means one of two things – it barely works, or they're saving a real announcement for later. either way, worth watching
conclusion
zoom out and a pattern emerges. the headline numbers on qwen 3.7 max are competitive but not revolutionary – it trades wins with claude opus 4.6 across most benchmarks, loses some, wins some. the real story isn't in the scores. it's in the methodology choices alibaba is making: training for persistence over hours, carrying reasoning across long tasks, decoupling models from frameworks, and using the model to supervise itself. these are bets about what matters for the next generation of agents – not raw iq on a test, but stamina, memory, transferability, and self-correction
whether those bets pay off is the real question. but it's a more interesting question than "did they beat opus on gpqa"


