 Addy Crezee
Addy Crezee

new bench evaluating code mergeability for the first time dropped yesterday. here’s the breakdown
@cognition released frontiercode on june 8, a benchmark that moves past functional correctness and asks whether a maintainer would actually merge a model's pr
the suite was built by 20+ open-source maintainers from 36 flagship repos, including celery, budibase, uppy, mattermost, and jsonschema
six axes are scored:
• behavioral correctness (does the patch actually solve the problem described in the task?)
• regression safety (does the patch avoid breaking anything that already worked?)
• mechanical cleanliness (does the patch pass the project's automated checks: build, lint, formatter, and style tooling?)
• test correctness (are the tests the agent wrote actually meaningful? they have to exercise the new behavior, not just pass trivially)
• scope (does the patch touch only what it needs to? no unrelated edits, drive-by refactors, or sprawl into other files)
• code quality (is the code idiomatic and readable?)
each rubric item is either a blocker or a non-blocker; failing any blocker scores zero. three novel methods back the rubric:
1. reverse-classical tests – the agent has to write its own tests for the fix. to prove those tests are meaningful, frontiercode runs them against the original, unfixed codebase. if they still pass there, the agent didn't actually test the bug; a real test should fail on broken code and pass on fixed code
2. scope checks – verify the patch doesn't sprawl. they combine fixed rules (which files may or may not be touched), size limits (lines changed, files modified), and an llm check that the edit stays in the right region of a file (e.g. inside the intended function rather than refactoring something nearby)
3. adaptive classical grading – open-ended tasks can have many valid solutions, and rigid reference tests often penalize a correct answer just because it named a function differently. a tool called mutagent uses an llm to make small, surgical edits to the reference tests so they line up with the agent's naming and structure, then runs them deterministically. the test logic stays intact; only the surface details adapt
the benchmark ships in three nested subsets: extended (150 tasks), main (100), and diamond (50 hardest). models are run 5 times at each reasoning effort, with the best level reported
the benchmark is unsaturated:
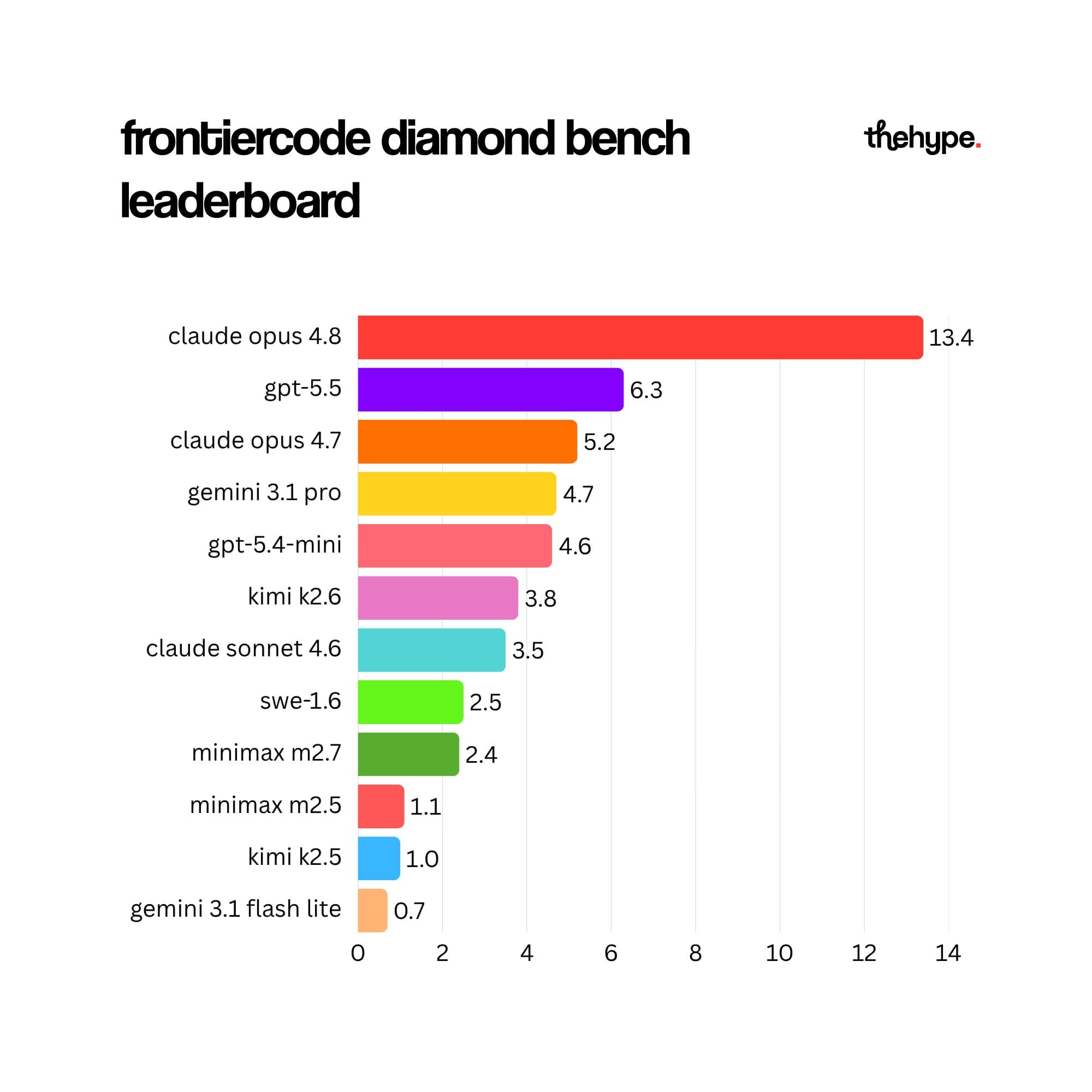
• on diamond, the leading model clears only 13.4%, and most frontier models land in the low single digits
• performance roughly triples moving from diamond to main, and roughly doubles again on extended, where the top model approaches the halfway mark
• open-source models trail the frontier by a wide margin across all three subsets
• token efficiency varies sharply, with the second-place model using up to 4x fewer output tokens than the leader for a better cost-intelligence tradeoff
tasks will not be released publicly to avoid contamination, but cognition is opening evaluation access to model creators
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40+ hrs of work by leading open-source maintainers.
— Cognition (@cognition) June 8, 2026
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code? pic.twitter.com/e1GD53x3T4


