Nick Trenkler
Nick Trenkler

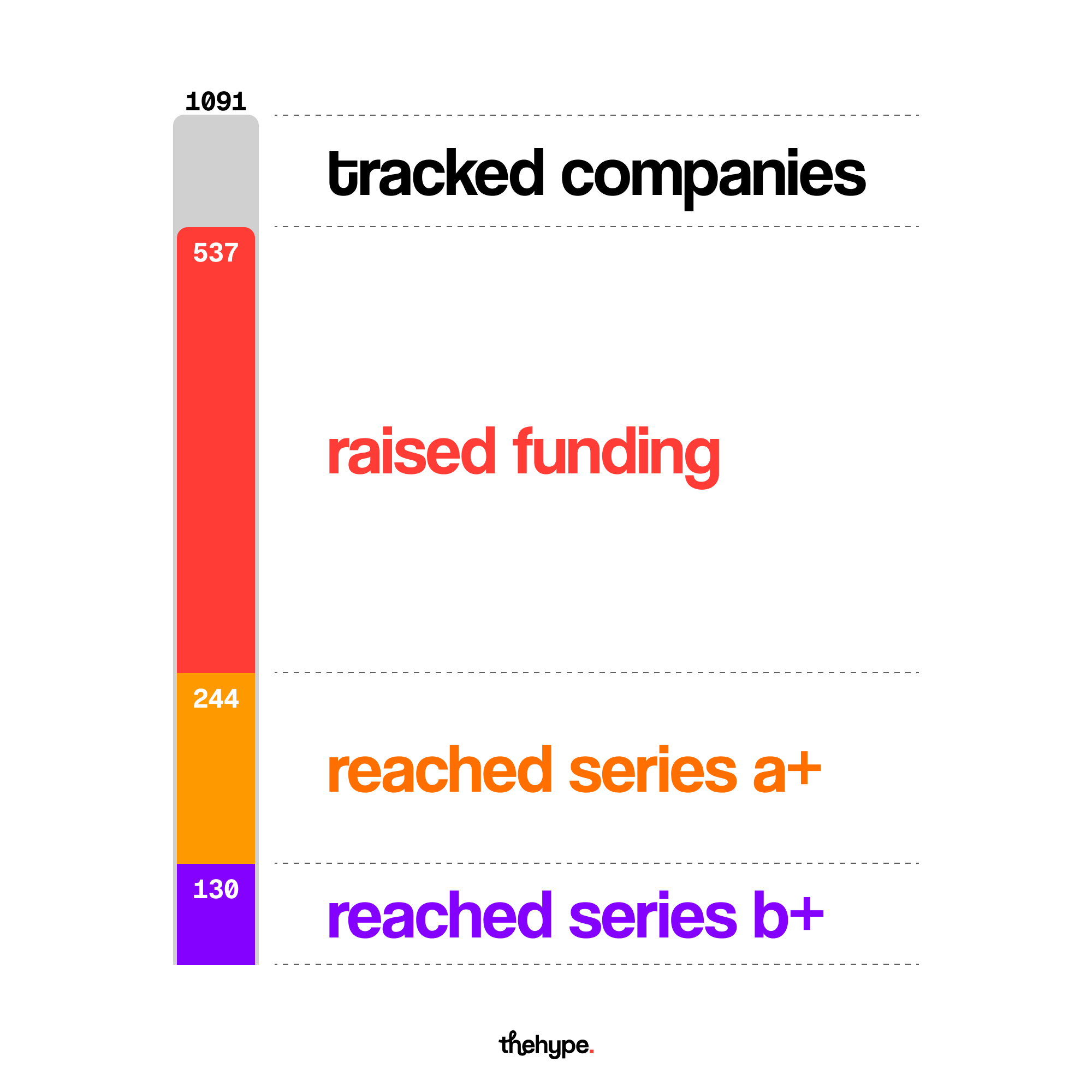
at first glance, market numbers tell a story of unstoppable momentum: agentic ai startups attracted $2.8 billion in global venture capital funding in just the first half of 2025, and the pace only accelerated from there. by early 2026, the sector counted more than 1,090 companies worldwide, with 573 having raised collectively over $24 billion and 27 unicorns minted. investors, it seems, cannot write checks fast enough.
but a subtler signal sits beneath the headline figures. through april 2026, agentic ai companies had raised $2.66 billion (a 144% increase over the comparable 2025 period), but across only 44 rounds. average round size had nearly doubled, and roughly 65% of disclosed deals were follow-ons rather than new seeds. capital is not spreading out - it is concentrating, and the market is beginning to sort itself into a small number of winners and a much larger cohort of eventual casualties.
this raises the question that investors and strategists need to sit with: if agentic ai is genuinely expected to transform the software industry, why are hundreds of startups racing to build on top of the same foundational models, in the same application categories, for the same enterprise buyers - and why are sophisticated investors funding them anyway? the answer to that question is both a story about the economics of platform transitions and a warning about where the durable value in this cycle is actually forming. most agentic ai startups are competing in the most visible layer of the stack, while the moats are forming underneath them.
In the AI gold rush, Jensen Huang is selling the picks and shovels. Nvidia's chips power AI companies around the world, helping the company become the first to surpass a $5 trillion market capitalization in late 2025.
— Forbes (@Forbes) June 3, 2026
Read more about how he and others made the… pic.twitter.com/lHLEv4NVhh
the gold rush above the stack
this is more of a history lesson that keeps repeating itself. when the internet emerged, capital flooded into web portals and e-commerce storefronts. when mobile arrived, thousands of app developers believed they had found the new frontier. when cloud computing matured, hundreds of saas companies launched into every conceivable niche. in each case, the technology was genuinely transformative; in each case, the majority of businesses built on top of it failed to build durable franchises, while a small number of companies, often the ones controlling infrastructure, distribution, or data, captured most of the lasting value.
agentic ai is following this script with eerie fidelity, but even faster this time. take cursor, for instance: the company had reached $200 million in annual recurring revenue by early 2025; by april 2026, it was in discussions for a round at over $50 billion. the trajectory from zero to two billion dollars in annualized revenue in roughly three years has no historical parallel in enterprise software.
yet, cursor's extraordinary trajectory is precisely the problem for most of its competitors: it proves that exceptional product-market fit exists somewhere in this layer, while simultaneously making the environment more treacherous for everyone else. every venture investor funding an agent startup is betting on finding the next cursor; most will not. the power law of venture capital holds that as little as 5 to 10 percent of investments yield the vast majority of returns. rational investors fund the cohort, knowing most of it will fail, because the alternative, which is missing the rare franchise winner, is worse than funding a hundred companies that disappear quietly.
The AI gold rush is rapidly drying up the supply of the one resource that AI developers can’t do without: computing power https://t.co/MjT8RljbxF
— The Wall Street Journal (@WSJ) April 13, 2026
the thin wrapper problem
the foundational tension in the agentic ai startup ecosystem is straightforward, even if its consequences are not yet fully priced in: the capabilities that startups are selling are largely rented from the same handful of model providers that determine whether those capabilities remain distinctive.
open-source models have reached frontier performance while inference costs approach zero, exposing what was always structurally true: pre-training large language models at scale is not a durable competitive moat. the gap between proprietary frontier models and open-weight alternatives is compressing faster than most application-layer startups modelled in their pitch decks. ai inference costs dropped 280-fold in roughly two years, according to stanford's ai index for 2025. the biggest ai trend right now is sharp drops in inference cost: roughly ten times per year for equivalent capability.
for an agent startup whose core value proposition is "we orchestrate frontier models to do x better than you can do it yourself," this cost collapse is not good news. it means that any workflow a startup builds can be assembled more cheaply tomorrow by a developer with access to the same open-source models and money. the replication barrier is approaching zero for an entire class of agentic applications.
the deeper problem is that model providers themselves have begun moving downstream. anthropic launched claude code in late 2025, directly competing with cursor and github copilot, prompting cursor itself to invest in developing proprietary models. in a three-week window in april 2026, anthropic launched managed agents in public beta at eight cents per session hour, while openai shipped its own model-native agent harness as an open-source sdk with no additional runtime fee. the message from both companies was unmistakable: the agent harness itself is becoming a feature of the underlying platform.
when the platform improves faster than the application, value migrates down the stack. this is not a new phenomenon, rather the familiar dynamic of every mature platform market, but the velocity of it in ai is unprecedented. startups that built their entire differentiation on top of gpt-4 discovered that gpt-4.1 made their advantage irrelevant. those who built on gpt-4.1 face the same prospect from the next generation - the ground keeps moving.
The "AI wrapper" problem in 2026:
— YC Insights. (@Aiagent_s) June 4, 2026
Opus 4.8 + any vertical ≠ a startup.
It's a product. Probably a feature.
The AI companies that survive:
Build proprietary workflows. Collect data that gets better with usage. Become the integration layer, not the model layer.
The API is not…
dependency is not a moat
building on someone else's infrastructure is not inherently fatal; salesforce was built on oracle databases, while shopify runs on cloud infrastructure it doesn’t own. however, there is a crucial difference between consuming commodity infrastructure and depending on a strategic partner who has both the capability and the incentive to compete with you in your core market.
the mobile app ecosystem offers the most instructive precedent. apple and google routinely absorbed successful app categories into their operating systems - from flashlights to qr scanners - eliminating standalone business cases overnight. the structural reality for agentic ai application startups is that openai, anthropic, google, and microsoft are building the equivalent of an operating system. any sufficiently valuable capability will eventually become a native feature.
api dependency compounds this risk in a second way: pricing. in 2025, openai generated approximately $3.7 billion in revenue while losing an estimated $5 billion, spending $1.35 for every dollar it earned - losses driven not by research and development, but by the cost of serving inference at scale. the current api pricing that startups have built their unit economics around is partly subsidised by venture capital and hyperscaler cross-subsidies. when those cross-subsidies eventually need to rationalise, startups whose gross margins depend on favourable api pricing will face an uncomfortable renegotiation. gartner predicts inference costs will fall over 90 percent by 2030, but has warned that companies masking architectural inefficiencies with cheap tokens today will find agentic scale elusive tomorrow. the cost floor and the revenue ceiling are moving towards each other for many agent businesses.
the enterprise trust barrier
if the technical risks facing agent startups were their only problem, the picture would be challenging enough. but the commercial reality of enterprise software introduces a second, equally daunting constraint: large organisations buy things slowly, carefully, and from vendors they trust with their legal exposure.
76% of enterprises cite data privacy and security as their top ai risk, according to gartner, while 77% of businesses are concerned about the accuracy of ai-generated outputs. these are not abstract worries - they are the practical experience of procurement teams and general counsel who have watched pilot deployments produce confident, plausible, and occasionally catastrophic errors.
mckinsey's 2026 ai trust maturity survey found the average responsible ai maturity score had reached only 2.3 on a five-point scale, with only about one-third of organisations reporting maturity levels of three or higher - and that agentic ai governance specifically was a dimension where most organisations remained unprepared. this is not, primarily, a technology adoption problem - rather, a trust and governance one. and trust moves at the speed of institutions, not demos.
for an agent startup selling into regulated industries, the friction is even more acute. security reviews that take weeks, data residency requirements that multiply integration complexity, legal teams that need to understand audit trails before signing procurement agreements - these are not bureaucratic inefficiencies that startups can optimise their way around. they are the actual landscape of enterprise sales. according to mckinsey's 2025 global survey on ai, 88% of organisations now report regular ai use, but nearly two-thirds have not begun scaling ai enterprise-wide. the gap between experimentation and scaled deployment is not primarily a capability gap; it’s a trust gap, and it advantages incumbents with established security certifications, existing contractual relationships, and names that do not require explanation to a risk committee.
Only 23% of companies are successfully scaling AI. and only 28% of leaders trust AI for decision-making. The most dangerous form of AI debt isn't cost. It's the trust gap from deploying AI on fragmented, unverified data.#AIgovernance #DataQualityhttps://t.co/SSI7HE23o0
— Isaac Sacolick (@nyike) June 3, 2026
the reliability problem nobody has solved
the economics of imperfect reliability deserve more attention than they typically receive in the venture community, where the tendency is to celebrate current capability benchmarks rather than examine compound failure rates in production.
tool misuse and incorrect tool arguments account for approximately 31% of production failures in enterprise agent deployments tracked between 2024 and 2025, according to a systematic analysis of production failures, followed by context drift and hallucination cascades. gartner has predicted that over 40% of agentic ai projects will be cancelled by 2027. the organisations cancelling those projects are not, in most cases, concluding that the technology does not work. they are discovering that they deployed without the resilience infrastructure that makes the technology trustworthy at scale.
the mathematics of step-by-step compounding explains why. if an agent achieves 95% accuracy on each individual action, which sounds impressive, a ten-step workflow will succeed only 60% of the time. a fifteen-step workflow succeeds only 46% of the time. most enterprise workflows involve more than fifteen steps. when hallucination rates exceed 30 percent in high-profile environments, users abandon the product even when later outputs improve, and a few wrong answers destroy trust more comprehensively than hundreds of correct answers can rebuild it.
this reliability ceiling has a direct economic consequence for startups. it forces them into expensive human-in-the-loop designs that erode the automation value proposition, or into highly constrained single-task workflows that limit total addressable market. neither path leads naturally to the general-purpose agent platforms that venture pitches tend to promise. the startups that are navigating this constraint most effectively are not those that have solved reliability abstractly, because nobody has yet, but those that have chosen domains where imperfect reliability is tolerable, tasks are bounded, and failures are visible and recoverable rather than silent and compounding.
⚠️ AI Agents are entering their REBUILD ERA
— AI For Success (@AiForSuccess) June 4, 2026
Enterprises deploying agents are hitting a reliability wall:
• Crashes mid-workflow
• State gets lost
• Costs spiral
Smart teams are rebuilding with reliability FIRST
Capability ≠ Dependability 🏗️#AI #Agents #Enterprise #Tech pic.twitter.com/KzWmloeFBk
the commoditization wave
beneath the reliability question lies a deeper structural dynamic: as foundation models improve, they systematically eliminate the differentiated capability of every agent built on top of them. according to epoch ai, ai inference prices are declining at a median rate of 50 times per year for equivalent performance, a pace that dwarfs moore's law. open-source models from alibaba's qwen, meta's llama, and deepseek are now competitive with proprietary frontier models on a growing range of benchmarks, at a fraction of the cost. the capability that justified a startup's existence in january may be table stakes by june.
this is not hypothetical. harvey, the legal ai company that reached a $190 million arr run rate and an $11 billion valuation in early 2026, discovered the dynamic directly: the company scrapped its proprietary vertical legal model after frontier reasoning models from google, xai, openai, and anthropic began outperforming harvey's custom model on harvey's own biglaw bench evaluation. a company that had bet on model-level differentiation was forced to pivot to workflow and data-layer differentiation instead. the lesson is stark: in a market where inference costs drop ten times per year and open-source alternatives reach frontier parity, functional capability alone produces nothing durable.
the question is not whether agent workflows will become commodities. they will, in the same way that crud applications, rest apis, and cloud databases became commodities. the question is what sits above the commodity layer and retains genuine pricing power.
where durable moats are emerging
here is what the evidence actually suggests about where sustainable businesses are forming in the agentic economy - and it is not primarily at the layer that is attracting most of the capital.
the companies demonstrating durable characteristics share a common structure: they do not merely use ai capability; they own something that ai capability cannot easily replicate. that something takes several forms.
proprietary data and workflow lock-in
harvey's actual moat is not its model; it is its corpus. between 2023 and 2025, harvey secured data-sharing arrangements with law firms and legal publishers that gave its models exposure to the structure of elite legal work - briefs, memos, red-lined drafts, the "how a cravath partner thinks" data. the corpus compounds: every month, harvey's dataset grows from the queries and feedback of over 100,000 lawyers across 1,300 firms. a competitor cannot buy that corpus; it has to earn it, and earning it takes years of being trusted inside institutions that do not give trust easily. harvey's platform now handles 400,000 agentic queries per day, with 25,000 custom workflows built by users, workflows that sit inside firms' daily operations and that represent a months-long migration to displace.
Knowledge is becoming commoditized. The defensible advantage is no longer just what the model knows, but the proprietary data, business context, controls, and auditability an enterprise brings to the model.
— david parry (@daviddryparry) June 4, 2026
I am ready for the day when LLMs are as normalized in my daily workflow…
distribution before the agent boom
servicenow's $2.85 billion acquisition of moveworks in 2025 illustrated a different kind of moat: distribution. servicenow, which already had thousands of ai agents deployed across its enterprise customer base, acquired moveworks to combine its agentic ai automation capabilities with moveworks' front-end ai assistant and enterprise search technology. what servicenow was really buying was the right to offer agent functionality inside existing contractual relationships to make the agent a feature of a platform that customers already trusted with their it and crm operations. the distribution moat pre-dated the agent product.
vertical depth at the cost of generality
the strongest application-layer businesses in this cycle look more like vertical software companies that have absorbed ai than like general-purpose agent builders. they have accepted the constraint of serving one industry deeply rather than many industries shallowly. that vertical depth creates training data advantages, regulatory expertise, workflow ownership, and reference customers that compound over time. it is not accidental that cursor's defensibility rests not just on its ai capabilities but on the depth of its integration into developers' existing codebases and workflows - its three-tier inference stack routes different cognitive tasks to different models depending on complexity and cost, giving it an architectural advantage that is difficult to replicate without the same installed base generating the data to train routing decisions against.
trust infrastructure and governance
a less glamorous but potentially durable category is companies building the observability, governance, and compliance rails that enterprises require before they will trust agents with consequential decisions. mckinsey has identified agentic ai governance as one of the least mature dimensions of enterprise ai readiness, with most organisations lacking the governance structures to oversee increasingly autonomous systems. the companies solving this problem are not in the press as frequently as the agent builders, but they are closer to the economic foundation on which the entire agentic economy must eventually rest.
Without proper governance, an AI agent might autonomously access sensitive data, expose personal information, or modify sensitive records. In our new short course: “Governing AI Agents,” created with @Databricks and taught by Amber Roberts, you’ll design AI agents that handle… pic.twitter.com/fm4nB1bVJR
— Andrew Ng (@AndrewYNg) October 22, 2025
the real future of agentic ai
none of this analysis disputes that agentic ai is transformative. the evidence for transformation is everywhere: servicenow reports that ai agents now resolve 90%t of it requests and 89% of customer support requests autonomously, cutting resolution times sevenfold; productivity gains in software development are measurable and compounding; enterprise ai governance maturity is rising, however unevenly. the technology will reshape knowledge work across every industry.
but technological success and startup success are not the same thing, and the history of platform transitions suggests they often diverge sharply. the railroad was transformative at the time, but railroad companies mostly destroyed capital. the internet was transformative, while most internet companies from the first wave are now gone. the question was never whether the technology mattered; it was always who would capture the economic surplus it generated.
in the agentic economy, the emerging answer to that question is not the companies building the most impressive agents. it is the companies controlling the infrastructure, data, distribution, trust, and economic rails on which those agents depend. model providers will capture the training and inference layer, competing fiercely with each other while eroding the capability differentiation of everyone above them. cloud hyperscalers will capture the compute layer, leveraging their existing enterprise relationships to become the default deployment environment for agent workflows. vertical incumbents with decades of domain data and institutional trust - the harveys and servicenows of the agentic era - will capture the workflow layer in markets where compliance and proprietary data create genuine moats.
the startups that are most likely to survive this sorting are not the ones with the best demos. they are the ones that recognized early that a transformative technology and a defensible business are separate problems, and solved both simultaneously. the winning organisations will have to successfully scale ai agents to production, created for detecting failure modes before deployment, not afterward. the same principle applies to building the companies themselves.
the fortune in the agentic economy will not be made by the companies building agents. it will be made by the companies that made it impossible to build agents without them.