Nick Trenkler
Nick Trenkler

there’s a quiet shift happening: agents are starting to browse the web more than humans. not hypothetically. not “soon.” already. and here are some stats:
- ai-driven traffic is growing ~8× faster than human traffic
- in some reports, bots are already overtaking humans as the dominant source of internet traffic
- agent activity itself is exploding — agentic interactions grew ~8,000% in 2025 alone
- meanwhile, 37% of users already start searches through ai instead of traditional web browsing
and inside systems:
- up to 65% of agent tools are now “action tools” (not just reading — actually doing things online)
- 57% of all agent queries are workflows + research tasks, not casual browsing
this isn’t just “ai usage growing.” and here’s the problem
most of the web is not ready (like, at all)
the uncomfortable reality: the modern web was never designed for autonomous agents, and large parts of it are effectively invisible or hostile to them. a few hard facts:
- ai crawlers don’t execute javascript. studies of crawler behavior show that most ai crawlers don’t run client-side js, don’t scroll, and only see what’s in the initial html payload. if your content loads dynamically after hydration, agents never see it.
- structured data adoption is weak. a large portion of the web still lacks consistent semantic markup (schema.org/json-ld), clean meta tags, or machine-readable structure. without it, agents must guess meaning rather than parse it.
- apis are rare. the majority of sites expose information only through ui interactions (forms, buttons, dynamic filters) rather than machine interfaces. this makes agents rely on fragile scraping instead of stable programmatic access.
- blocking by default. many cdn and security configurations unintentionally block ai crawlers and automated tools. some ai crawler traffic is blocked before it ever sees the page.
- the agentic layer is still tiny. only a small fraction of sites expose structured machine interfaces, publish machine-readable documentation, or support agent discovery mechanisms like llms.txt or agent manifests.
the result is a web where agents can technically “fetch” a page, but often can’t reliably interpret or use it.
where agents actually break
when you look at real agent behavior, failure modes repeat across sites and industries.
1. javascript-only rendering. if critical content is loaded client-side (react, spa frameworks), agents that fetch raw html simply don’t see it.
nohacks2. lack of semantic structure. without semantic html, clear headings, or structured data, agents can’t reliably identify what a page is about.
vercel3. no stable navigation model. humans infer structure visually; agents need explicit structure.
medium4. no programmatic interfaces. without documented apis or consistent endpoints, automation becomes brittle.
dev.to5. authentication and anti-bot walls. captchas, bot detection, and rate limiting block legitimate agents.
wired6. inconsistent or hidden state. agents struggle when state changes aren’t reflected in the dom.
linkedin7. no machine-readable contracts. inconsistent formats and changing schemas make automation unreliable.
arxivin short: agents don’t fail because they’re “not smart enough.” they fail because the web assumes a human with a browser, a mouse, and visual intuition.
so we tried to measure it
that’s where things got interesting. we started looking for a way to actually diagnose how “agent-ready” a website is — not in theory, but in practice. and we found a tool that does exactly that. a system that evaluates websites not on seo or ux, but on whether agents can:
- read them
- understand them
- interact with them
- and actually do things on them
how it works: level 0 – level 5 for the agent internet
in this table you see the methodology proposed by the silicon friendly project. it defines what “agent-readiness” means in practice, and how to measure it. the full description of the framework is available here:
https://siliconfriendly.com/levels/
how to optimize your website for agents
this guide walks you through exactly what to build or fix to pass each level – from basic readability to fully autonomous agent workflows.
l1 – basic accessibility
1. use semantic html
don’t build everything from <div>. use:
<header>,<nav>,<main>,<article>,<section>,<footer>- meaningful structure so an agent can infer page hierarchy
2. implement complete meta tags
include:
<title>- meta description
og:title,og:description,og:imagetwitter:card
this lets agents understand what the page is about without guessing.
3. add schema.org structured data
embed JSON-LD describing:
- products
- organizations
- articles
- FAQs
- events
this gives agents explicit meaning instead of guessing from layout.
4. don’t block basic access
avoid CAPTCHAs or anti-bot walls on public content.
protect actions, not reading.
5. ensure content is server-rendered
your main content must be visible in raw HTML, not only after JavaScript runs.
6. keep URLs clean
prefer:
/products/shoes
over:/page?id=9982&view=full&sort=desc
if you fail L1: agents can’t even read you. nothing else matters.
l2 – discoverability
can agents find things on your site?
1. ship a proper robots.txt
allow legitimate bots and avoid accidental blocks.
2. provide an XML sitemap
list all major pages and keep it updated.
3. publish llms.txt
a human-readable file explaining:
- what your product is
- where docs live
- how to use your API
think of it as a landing page for AI agents.
4. publish an OpenAPI spec
document endpoints, inputs, outputs, and errors in machine-readable format.
5. maintain machine-readable docs
docs should be:
- text-based
- consistently structured
- versioned
- linkable by section
6. avoid hiding core info in media
don’t lock critical info inside:
- images
- videos
- PDFs only
if you fail l2: agents don’t know what you offer or where to go.
l3 – structured interaction
can agents actually talk to your product?
1. provide a structured API
REST or GraphQL with predictable endpoints.
2. return consistent JSON
responses must be:
- predictable
- versioned
- schema-consistent
3. support search and filtering
enable:
- filters
- pagination
- sorting
this reduces scraping and guessing.
4. publish an agent card
host at:
/.well-known/agent.json
describe:
- capabilities
- auth methods
- supported actions
5. document rate limits properly
return:
429when limitedRetry-Afterheader
6. return structured errors
errors should include:
- code
- message
- actionable context
if you fail l3: agents can read, but can’t interact reliably.
l4 – agent integration
can agents do real work here?
1. provide an mcp server
implement a model context protocol server so agents can:
- discover tools
- call functions
- read structured responses
2. support WebMCP
let browser-based agents interact without custom integrations.
3. support write operations
enable:
POSTPUTPATCHDELETE
agents must be able to change state, not just read it.
4. provide agent-friendly auth
support:
- api keys
- oauth client credentials
- scoped tokens
avoid login flows meant only for humans.
5. support webhooks
allow agents to receive:
- event notifications
- state changes
- asynchronous results
6. implement idempotency
allow safe retries via idempotency keys.
if you fail l4: agents can read, but not reliably act.
l5 – autonomous operation
can agents operate without a human watching?
1. support event streaming
use:
- server-sent events
- websockets
- realtime apis
2. enable agent-to-agent negotiation
allow agents to:
- discover each other
- negotiate capabilities
- coordinate tasks
3. provide subscription & management APIs
allow agents to:
- subscribe to updates
- manage settings
- configure behavior
4. support workflow orchestration
agents should be able to:
- run multi-step flows
- track state
- recover from failure
5. enable proactive notifications
notify agents when:
- data changes
- thresholds hit
- actions complete
6. enable cross-service handoffs
allow agents to:
- pass tasks between systems
- coordinate across APIs
if you fail l5: agents still need humans to glue everything together.
we checked big tech. results are… bad
even well-designed websites – the kind humans love – often look like static brochures to agents.
apple.com – l1 (basic accessibility)
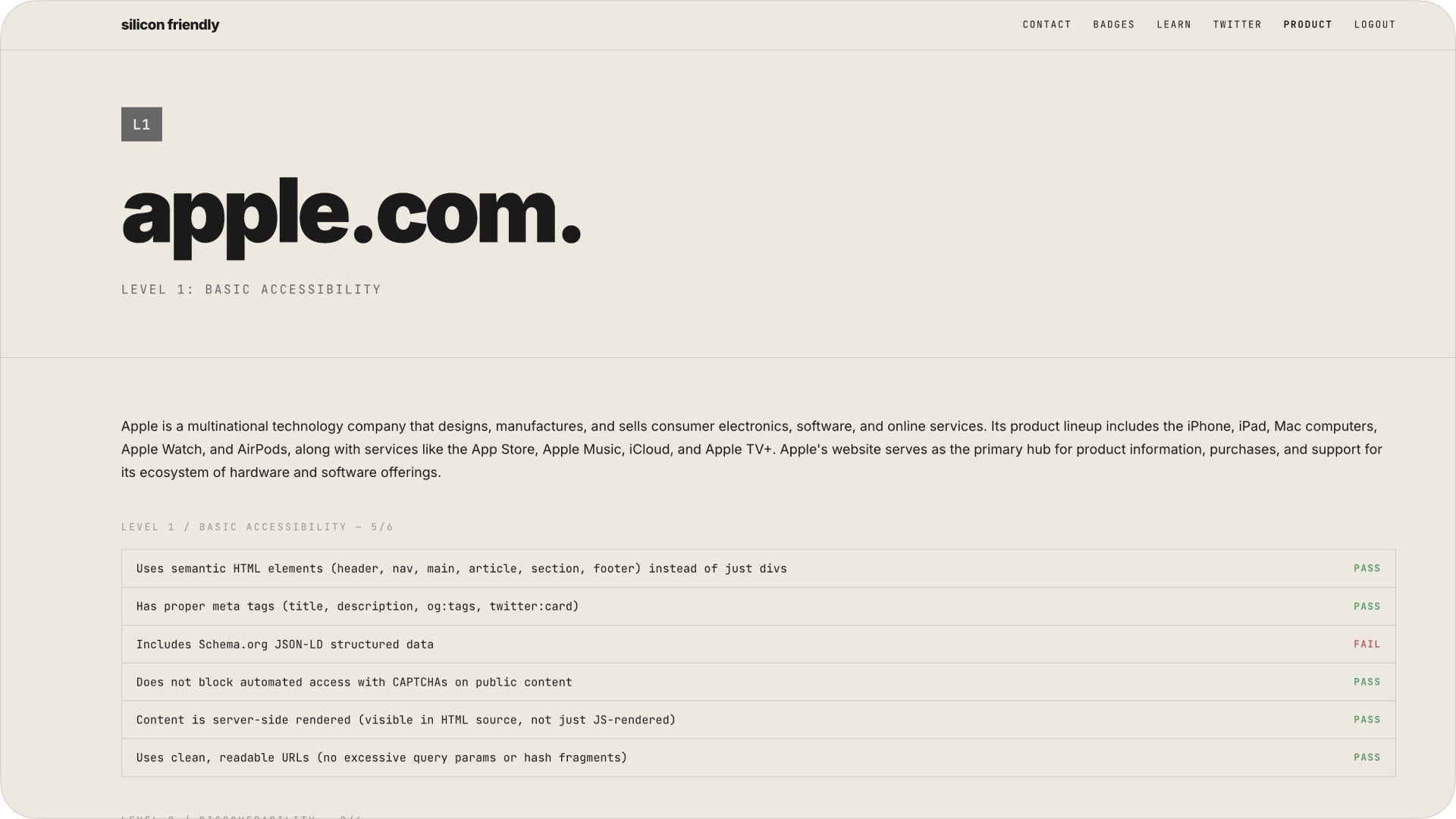
apple – one of the most polished consumer websites on earth – barely passes level 1.
- readable? yes
- discoverable? partially
- usable by agents? no
no llms.txt. no api surface. no structured interaction. for an agent apple.com is basically a brochure.
vercel.com – l3 (structured interaction)
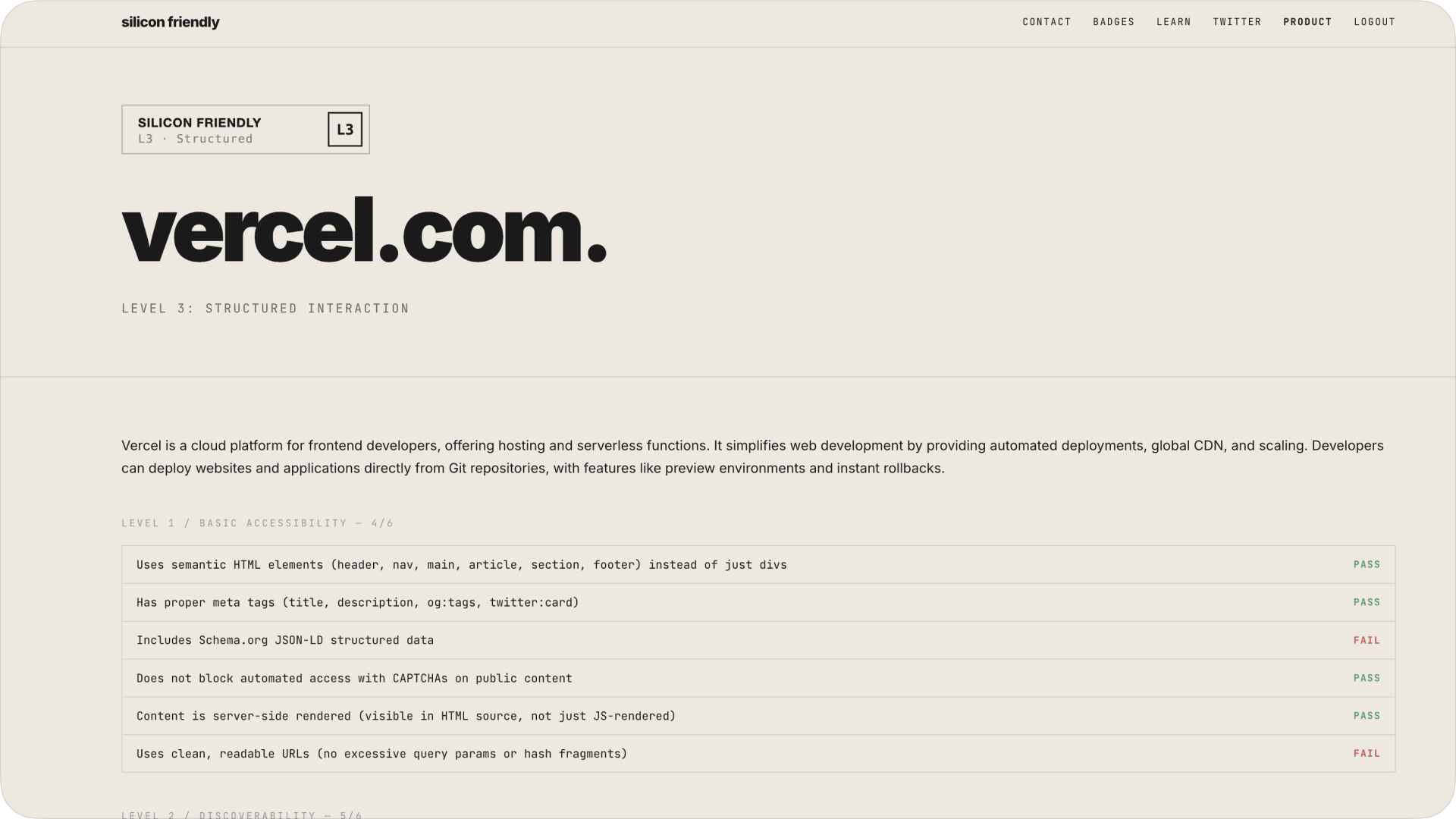
vercel does much better:
- strong docs
- api-first mindset
- llms.txt present
but still missing key pieces like:
- agent cards
- deeper agent workflows
translation: dev-first companies are ahead, but still not “agent-native.”
ibm – also stuck low
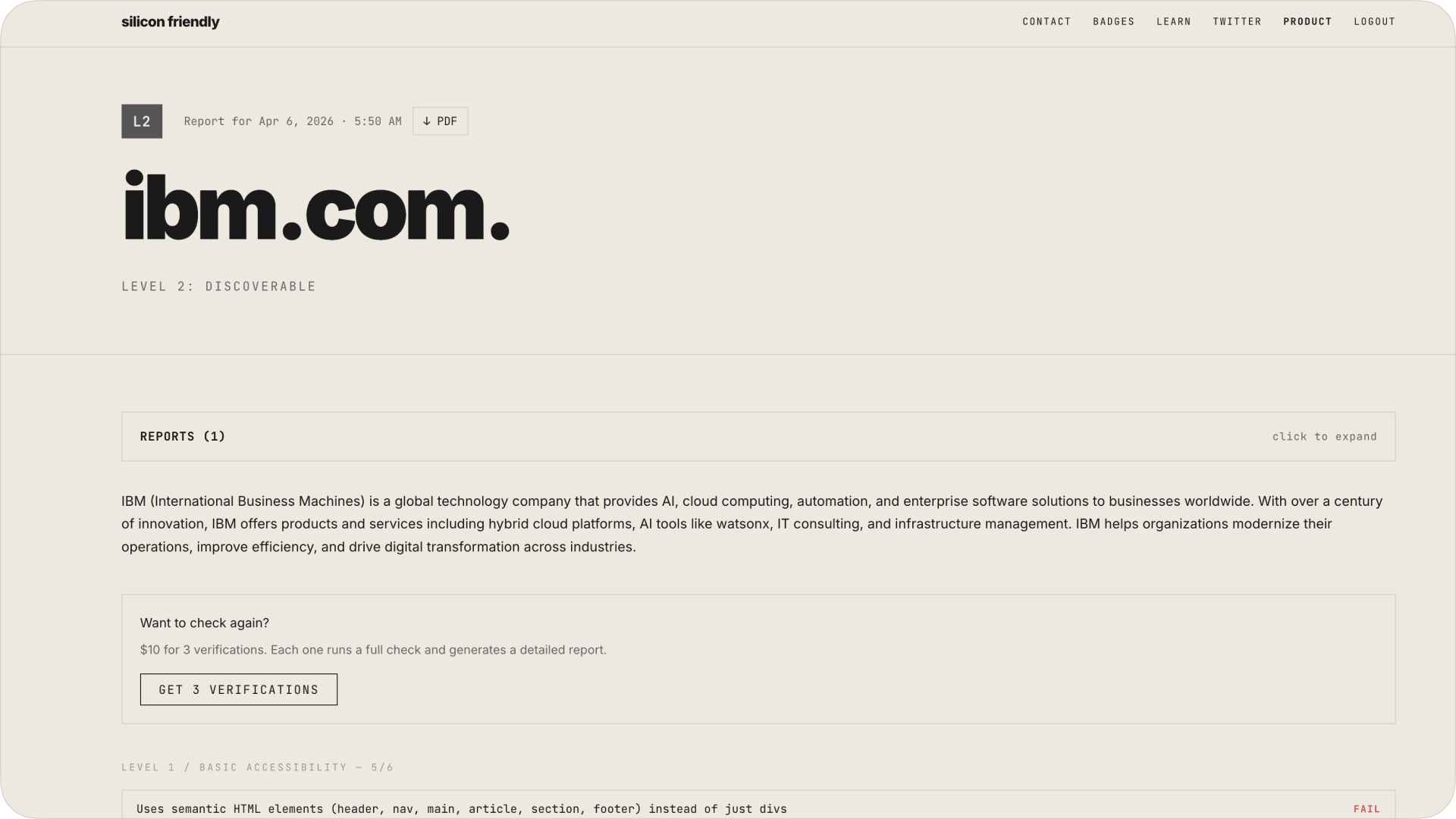
even legacy enterprise (which loves APIs) doesn’t translate cleanly to agents.
lots of infra, but:
- no standardized agent entrypoints
- no consistent schemas
only 13 websites on earth hit l5
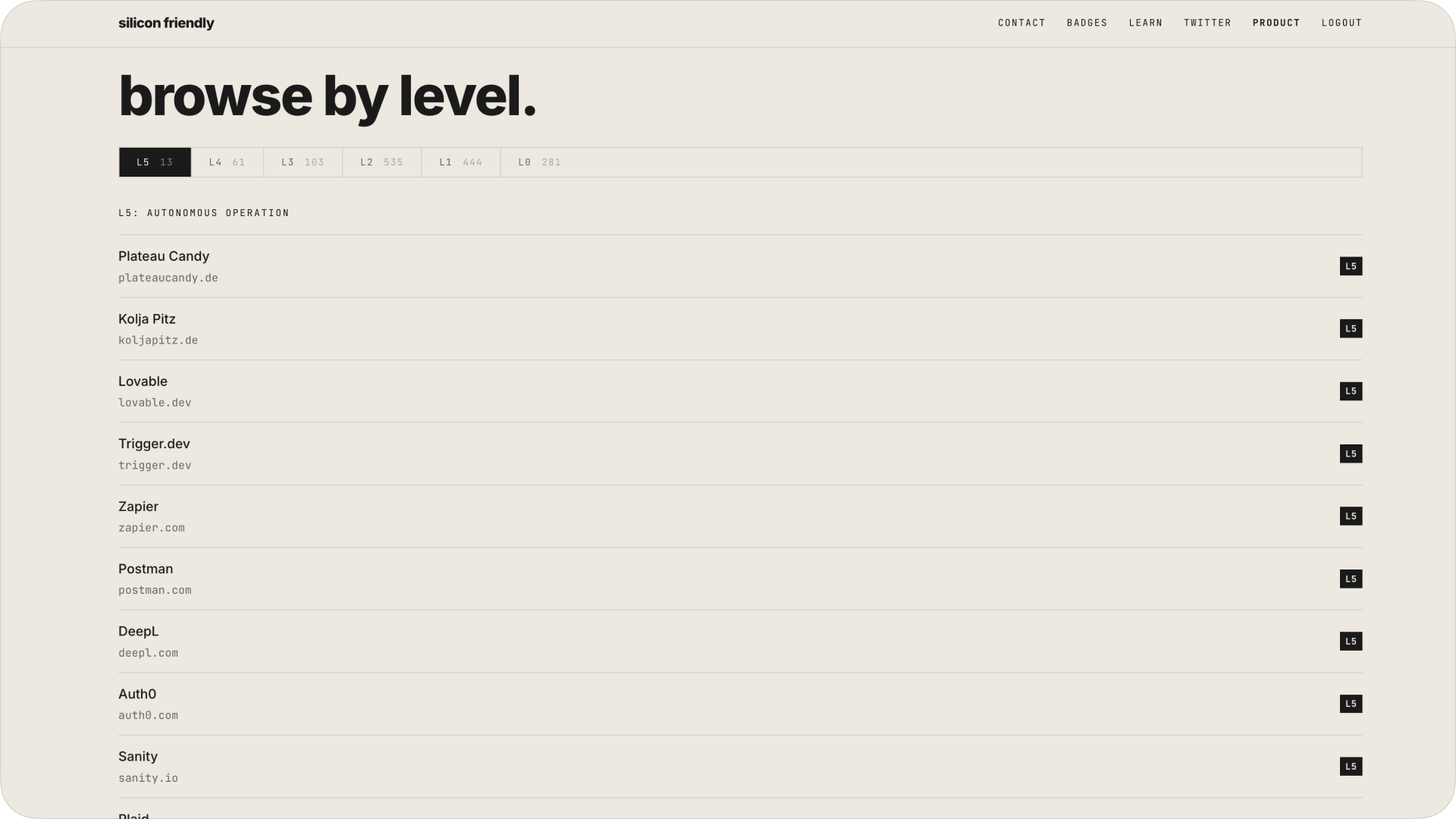
this is the wild part. siliconfriendly has a public ranking of agent-ready sites. out of hundreds analyzed:
- l5 (fully autonomous – agents can operate end-to-end): 13 websites
- l4 (agents can act – authenticated actions, workflows): 61
- l3 (usable via api – structured interaction): 103
- l2 (discoverable – agents can find and understand the site): 535
- l1 (readable – basic parsing and accessibility): 443
- l0 (hostile to agents – broken or blocked): 279
the l5 list is basically who you’d expect:
- zapier
- postman
- plaid
- paypal (dev)
- square (dev)
- auth0
- sanity
- trigger.dev
- deepl
- razorpay
- lovable
- plateau candy (random but interesting)
pattern is obvious: api-first companies win.
someday soon, i'll just ask my agent to check it for me. but not today — because if the agent messes up, i'm f**ked.”

what founders should take from this
this isn’t about compliance. it’s about distribution.if agents become the interface:
- seo becomes “agent optimization”
- ux becomes “api + schema design”
- landing pages become secondary
practical takeaway: if you’re building today, start with:
- expose your core actions via api
- document everything (machine-readable)
- add llms.txt
- think: “can an agent use this without a browser?”
because someone else will.