 Addy Crezee
Addy Crezee

here’s what it means and how they achieved it
the team pointed qwen3.7-plus at apple's native stocks app and told it to reproduce it. no manual instructions, no step-by-step guidance. the model:
• explored the real app autonomously to understand the ui layout and feature logic
• wrote swiftui code from its own interaction records
• pulled in live market data via the longbridge api
• compiled and launched the replica itself
• then ran 10 functional tests – real-time quotes, stock switching, multi-period views, search filtering, detailed stats panel – all passed
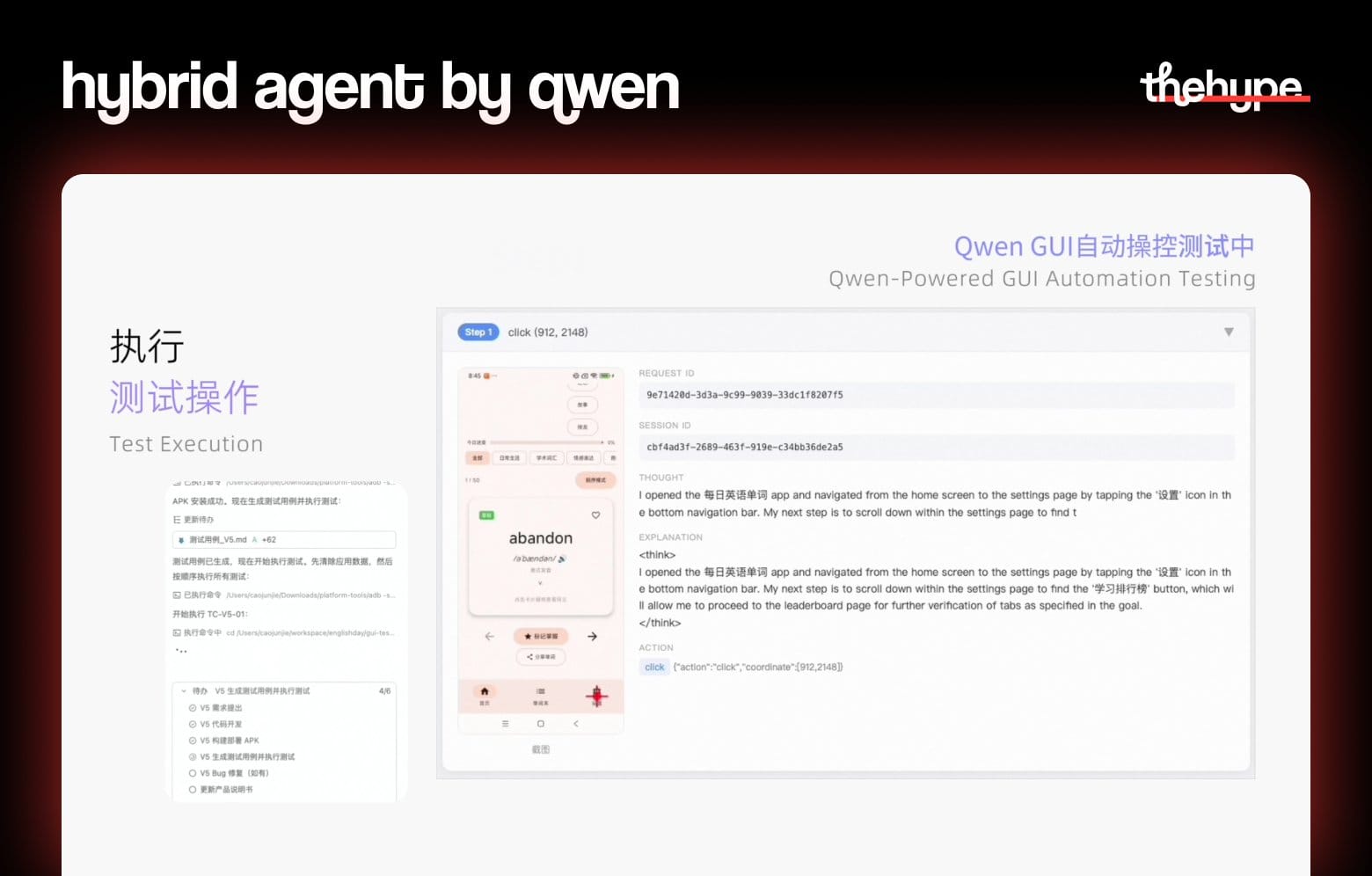
how they built this. the underlying system isn't just a coding model. it's what qwen calls a multimodal hybrid agent – a closed loop that looks like this:
see - think - write - act - verify
the model perceives a real screen, reasons about it, writes code, executes gui (graphical user interface) interactions, checks the output, and iterates. gui and cli in a single continuous loop. no context switching, no human in the middle
why this is different from regular coding agents. most coding agents write code and stop. the verification step – does this actually work? does it look right? – gets handed back to a human
qwen3.7-plus closes that gap. it operates the gui to validate what it built, catches failures, and loops back. the human reviews the final output, not every intermediate step
the numbers behind it. on screenspot pro – the benchmark for gui element localization – qwen3.7-plus scores 79.0
• gpt-5.4 sits at 67.4
• gemini-3.1 pro at 68.1
this isn't a marginal win. the model is operationally better at reading and controlling interfaces than the current frontrunners
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
— Qwen (@Alibaba_Qwen) June 1, 2026
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with… pic.twitter.com/T3YTDnkE1D


