 Nick Trenkler
Nick Trenkler

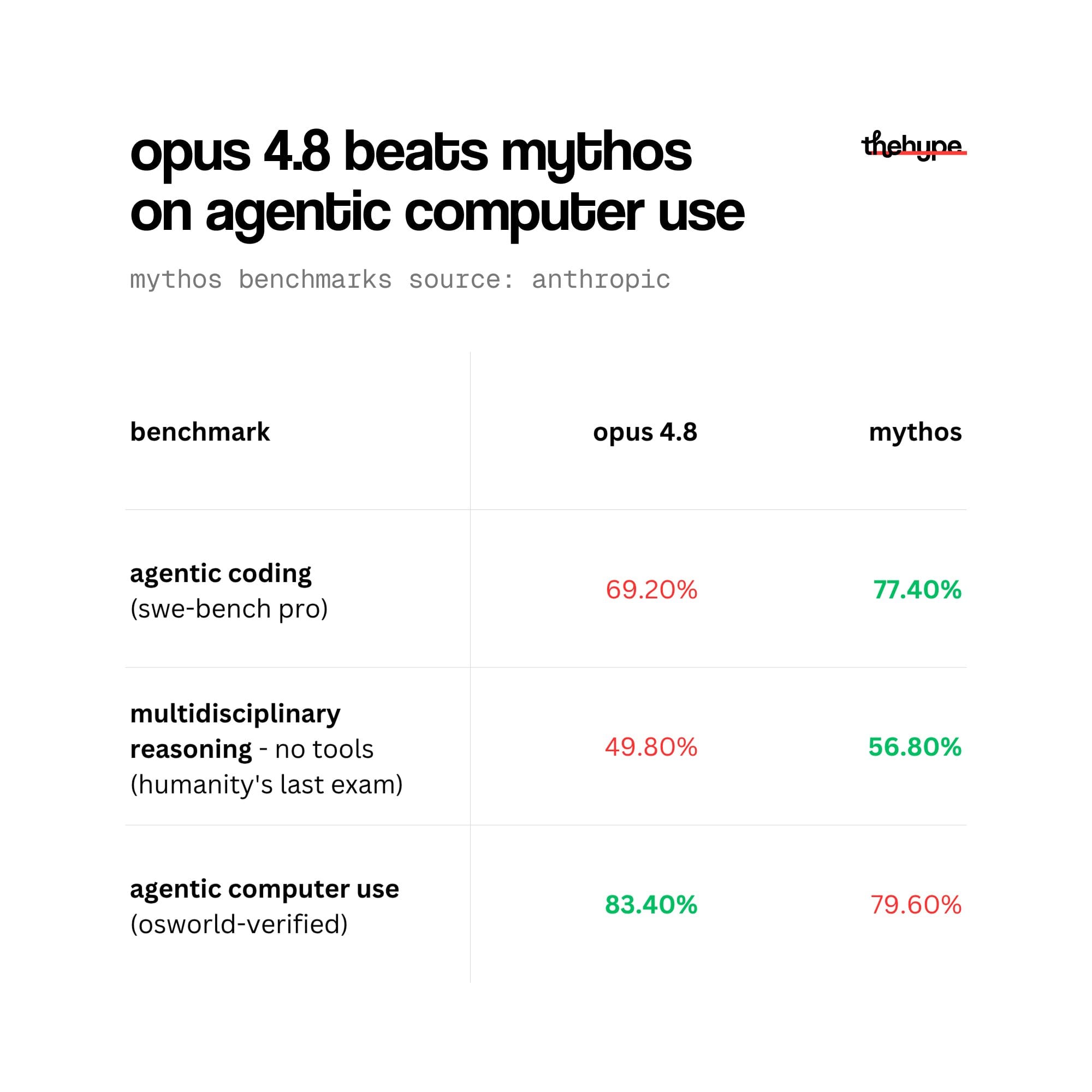
osworld-verified bench tests ai on real computer tasks – opening apps, filling forms, navigating browsers. each task is pass/fail. the % is simply how many tasks the model completed successfully out of the total
83.4% vs 79.6% – a nearly 4% gap on pass/fail tasks isn't noise. it's a pattern
public models are closing the gap faster than anyone expected. if anthropic doesn't open mythos to the mass market soon, the window closes
and according to the opus 4.8 release notes – it already is. mythos goes public in weeks
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
— Claude (@claudeai) May 28, 2026
Available today at the same price. pic.twitter.com/EufxL7T1kb


