 Nick Trenkler
Nick Trenkler

thehype analyzed a post by @MiniMax_AI's head of engineering announcing the m3 model and its architecture. here's what we've found out
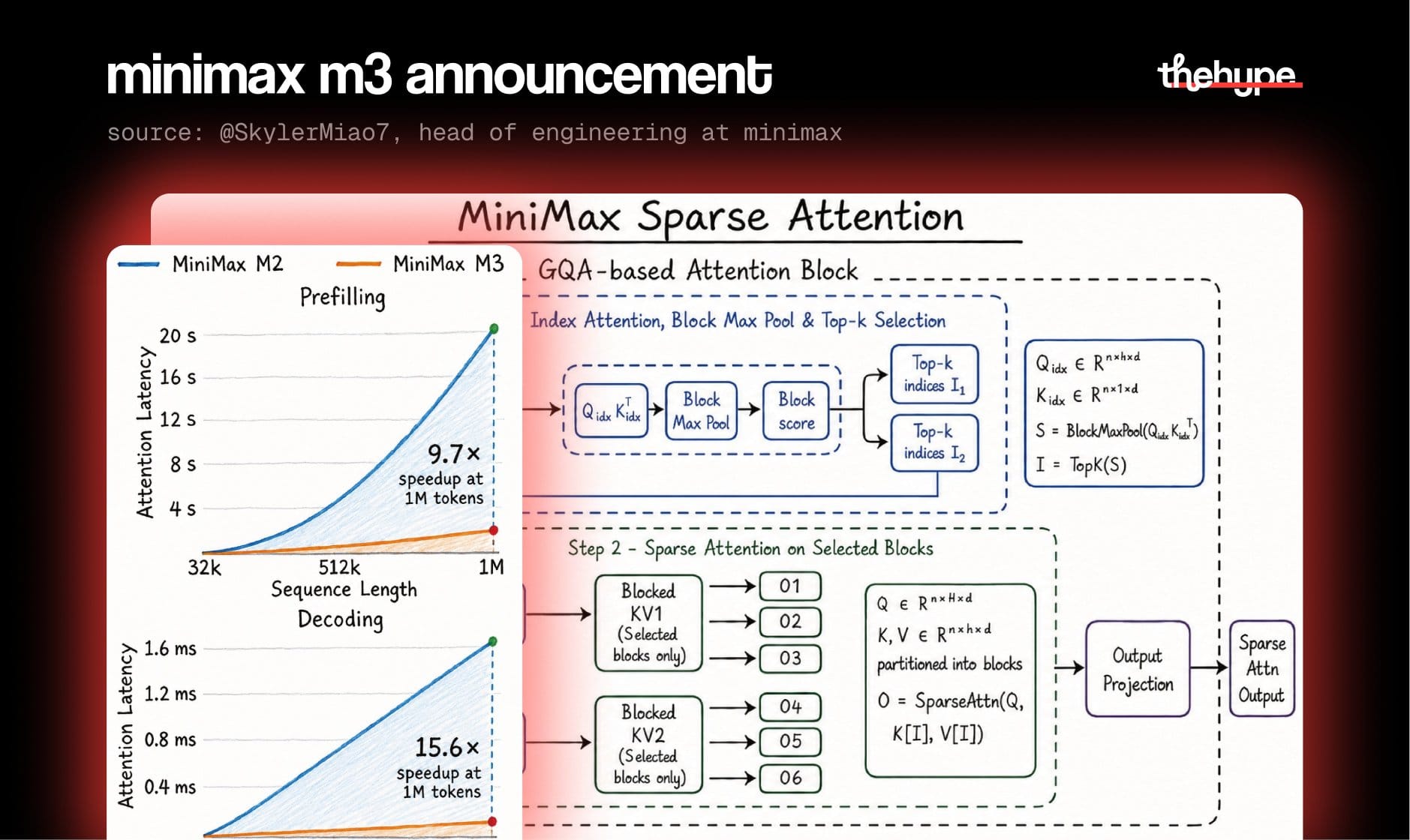
in most llms, every time the model needs to understand something or generate the next word, it has to scan the entire conversation history from top to bottom. this process is called attention – the model "attends" to everything you've said, weighing what's relevant. normally this happens in one pass: read everything, all at once, every single time
m3 splits this into two separate passes instead:
• pass 1 – the scout. a tiny "scout query" skims the whole context and scores blocks of tokens. it picks the top-k most relevant blocks. think skimming a table of contents
• pass 2 – the real read. the full attention queries only look at the blocks the scout flagged. everything else gets skipped
different query groups can focus on different parts of the context
at 1 million tokens of context, m3 is way faster than normal attention:
• loading and processing a huge prompt (prefilling): 9.7x faster
• generating each new token (decoding): 15.6x faster
why is decoding even faster? because normally, every time the model spits out a single word, it has to re-read the entire conversation history. that's like flipping through a whole book just to write one sentence. m3's scout already flagged the relevant pages, so it only checks those. massive time saver
at 32k tokens, m3 and normal attention are basically the same speed. the scout step adds a tiny bit of overhead, so it only makes sense when the context is really long. this thing is built for giant conversations and agent tasks, not short chats
what this actually means:
1. context window is going way up. their previous model m2.7 capped at 200k tokens. m3 is benchmarked at 1m – a 5x jump
2. the way m3 chooses which blocks to read isn't based on fixed rules (like "always skip every other block"). it learns what's relevant on the fly based on what you're asking
3. if quality holds, m3 can serve million-token agentic workloads at near-200k prices. nobody else is touching that
#MSA #OpenSource #M3
— MiniMax (official) (@MiniMax_AI) May 26, 2026
🫣😎 https://t.co/Lwyr5Y8xV0


