 Nick Trenkler
Nick Trenkler

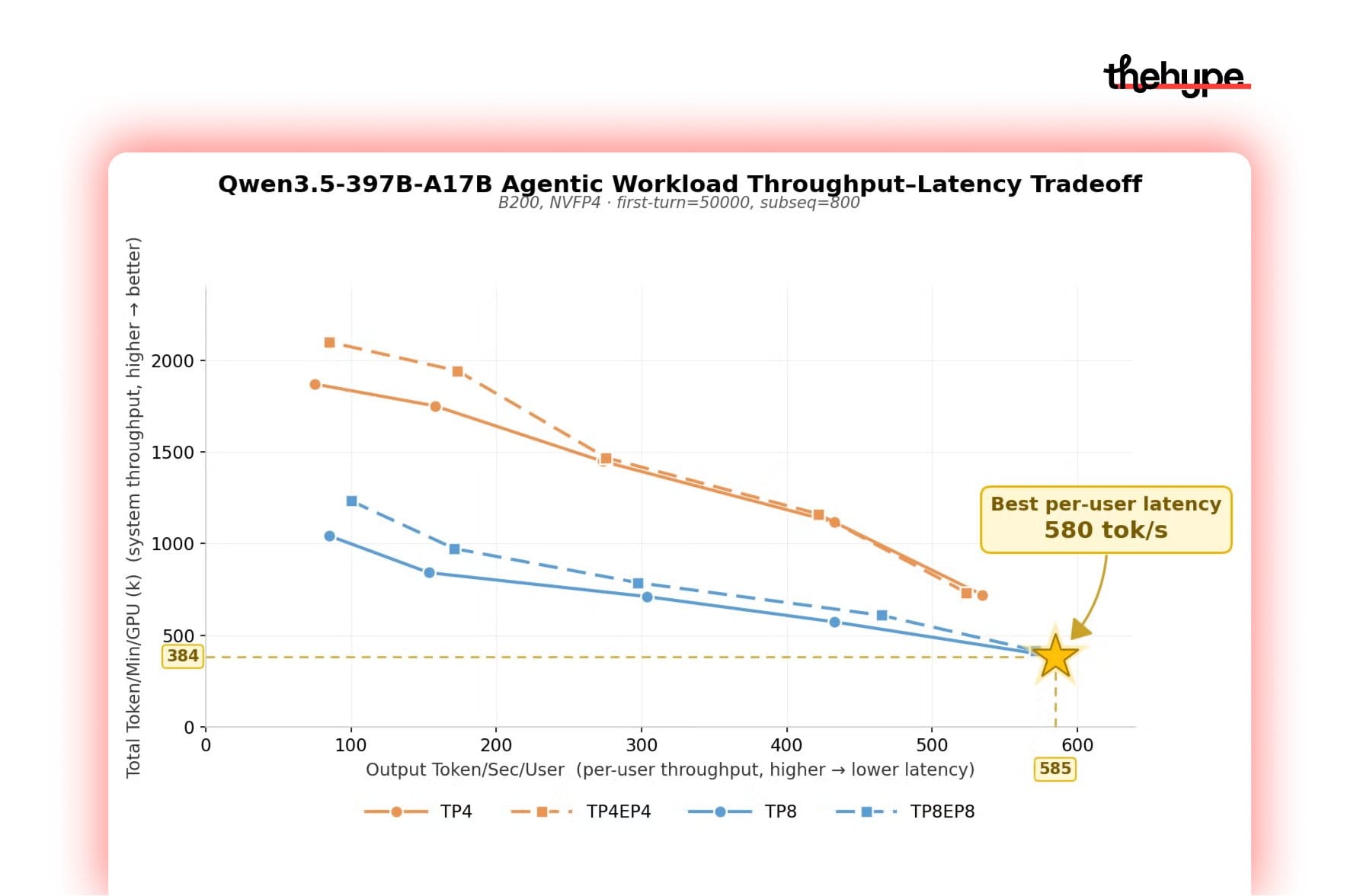
The speed-of-light optimization for Qwen3.5 on the TokenSpeed inference engine is a significant milestone, achieving a record-breaking 580 tokens per second (tps) for agentic workloads on NVIDIA GPUs.
— PyTorch (@PyTorch) May 27, 2026
In the PyTorch Foundation's latest community blog post, you can learn all… pic.twitter.com/s70Wdsx2aB
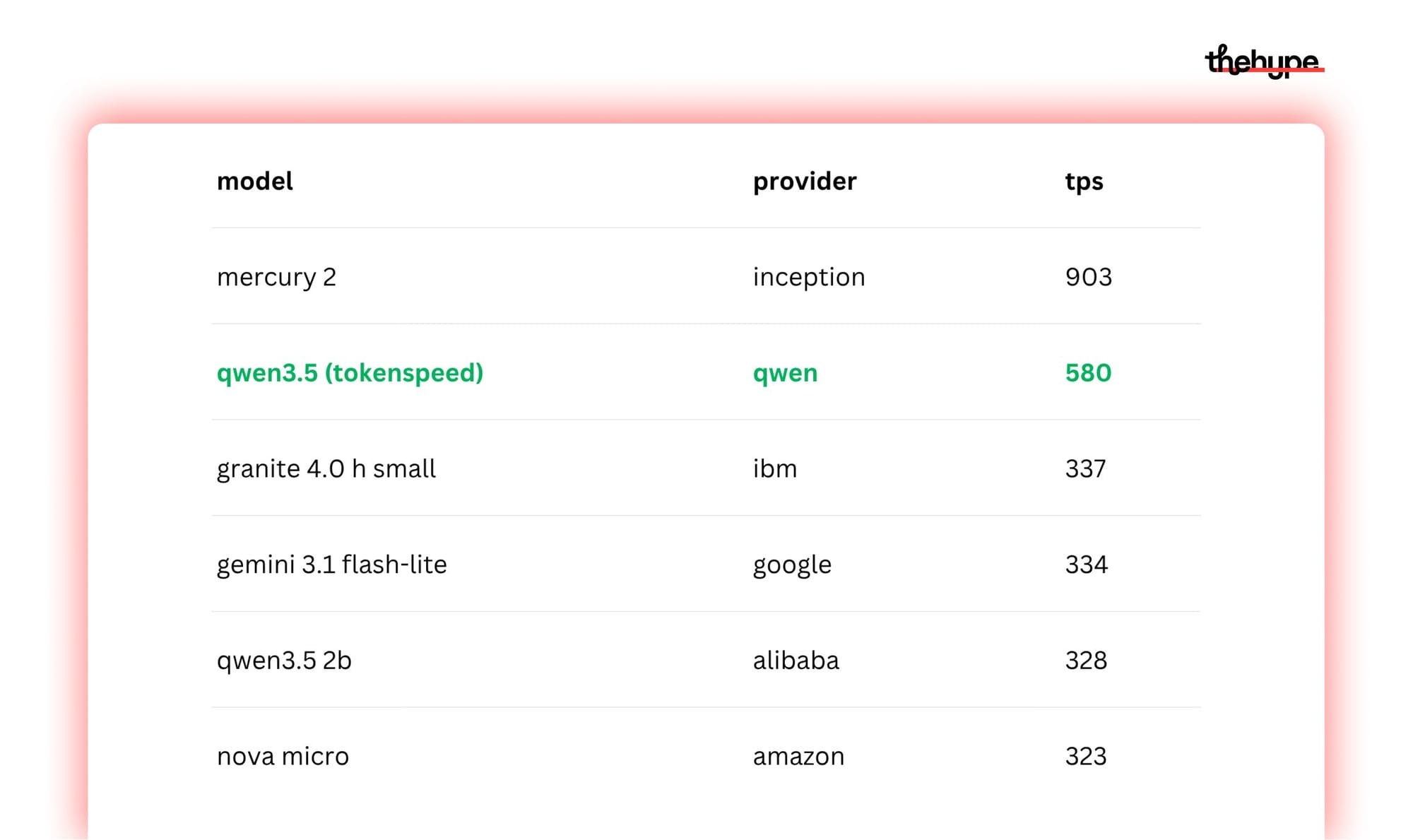
580 tokens per second is genuinely crazy. for context, if qwen3.5 ran at this speed by default, it would rank #2 on artificial analysis's speed leaderboard – sitting between mercury 2 (903 tok/s) and granite 4.0 h small (337 tok/s). and unlike those two, qwen3.5 is a 397b-parameter flagship model, not a small or specialized one
how they did it
tokenspeed is an open-source inference engine (the software layer that runs the model) built specifically for agent-style workloads. it stacks several tricks:
- reuse past work – agent conversations repeat the same context constantly (system prompts, history). tokenspeed caches it and skips redoing 90%+ of repeated processing
- point to data instead of copying it – during speculative decoding (predicting likely next words in parallel to go faster), the old method copied huge chunks of internal state every step. tokenspeed just updates a pointer (a reference saying "the answer is over there") instead of moving the data
- run things in parallel – gpus can handle multiple jobs at once. tokenspeed splits independent work across parallel lanes so nothing waits its turn
- bundle small operations – fuses many tiny gpu calls into single bigger ones, cutting overhead
- keep the gpu fed – restructured the workflow so the cpu (regular processor) never pauses to wait on the gpu
- split workload across machines – input reading and answer generation can run on separate servers, connected by rdma (direct memory transfers between machines, skipping normal os overhead)
but it's not cheap
this result was achieved on 8 nvidia b200 gpus – the latest top-tier hardware. pricing roughly looks like:
- cloud rental: $2.25/hour (3-year reserved) up to ~$14.24/hour on-demand, per gpu
- buying outright: $30,000–$40,000 per gpu
so the setup behind 580 tok/s costs somewhere between ~$140/hour to rent or ~$240k–$320k to own – and that's just the gpus, not the surrounding infrastructure
the bigger lesson
this is the interesting part: the model itself didn't get smarter or faster. qwen3.5 is the same model running everywhere else. what changed is the software wrapping it and the hardware underneath it. the 580 tok/s result is a cocktail – model + inference engine + gpu generation + parallelism strategy – and any single ingredient missing kills the numberwhich means ai performance isn't really about the model anymore. it's about the whole stack working together. and most of that stack is still earlyso the real takeaway: we haven't seen what these models can actually do yet. today's benchmarks reflect today's stack – not the model's ceiling. as engines mature, hardware iterates, and optimization patterns spread to cheaper gpus, the same models will run dramatically faster and cheaper. the true power of current ai is still locked behind infrastructure that hasn't caught up yet


