 Addy Crezee
Addy Crezee

hidream-o1-image-dev-2604 is ranked #1 across all open weight text-to-image models on the artificial analysis text-to-image arena
what makes this model interesting is how it's built. many other image models (for example gpt image 2) use a vae, a separate component that compresses images into a smaller latent space before the main model works on them. hidream skips that entirely. it works directly on raw pixels using something called a pixel-level unified transformer. text, images, layout instructions, everything goes into one shared token space
it's also only 8 billion parameters. to put that in perspective, flux.2 dev uses 24 billion parameters plus a 32 billion parameter text encoder, 56 billion total. qwen image uses 7 billion plus 20 billion. hidream achieves better or comparable results with just 8 billion total, no extra encoder, no vae. that's unusually efficient
it handles multiple tasks in one model. text-to-image is the main one, but it also does instruction-based image editing, like "remove the earphones" from a photo, and subject-driven personalization where you give it several photos of a person or object and it places them in a completely new scene. it can render long passages of text accurately in images, in multiple languages, which most models struggle with. it generates natively at up to 2048 by 2048 pixels
the model and code are released under the mit license, so commercial use, modification, and redistribution are all permitted
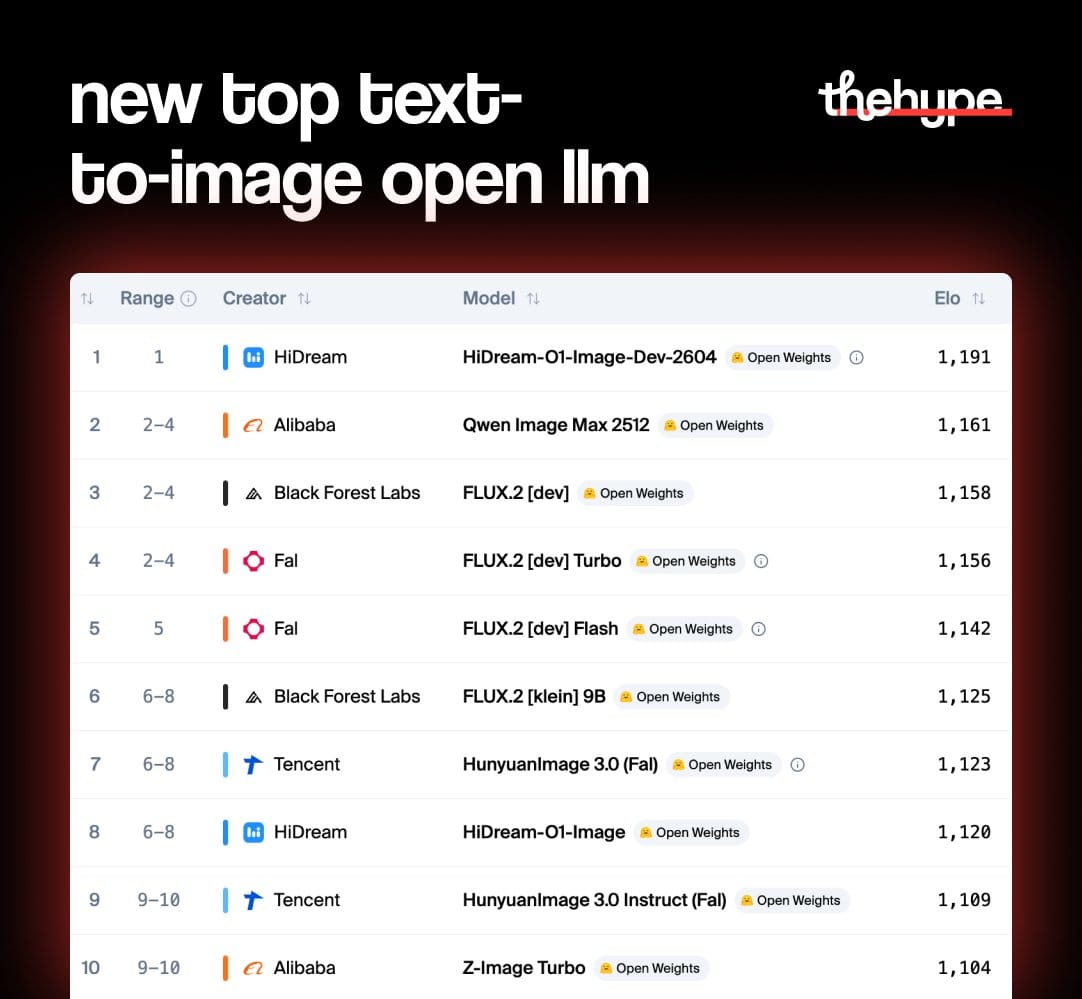
HiDream-O1-Image-Dev-2604 debuts as the leading open weights Text to Image model in the Artificial Analysis Image Arena, with the base HiDream-O1-Image and HiDream-O1-Image-Dev also available open weights but landing lower on the leaderboard@HiDream_AI's O1-Image family spans… pic.twitter.com/Eju8OLTppE
— Artificial Analysis (@ArtificialAnlys) May 31, 2026


