Nick Trenkler
Nick Trenkler
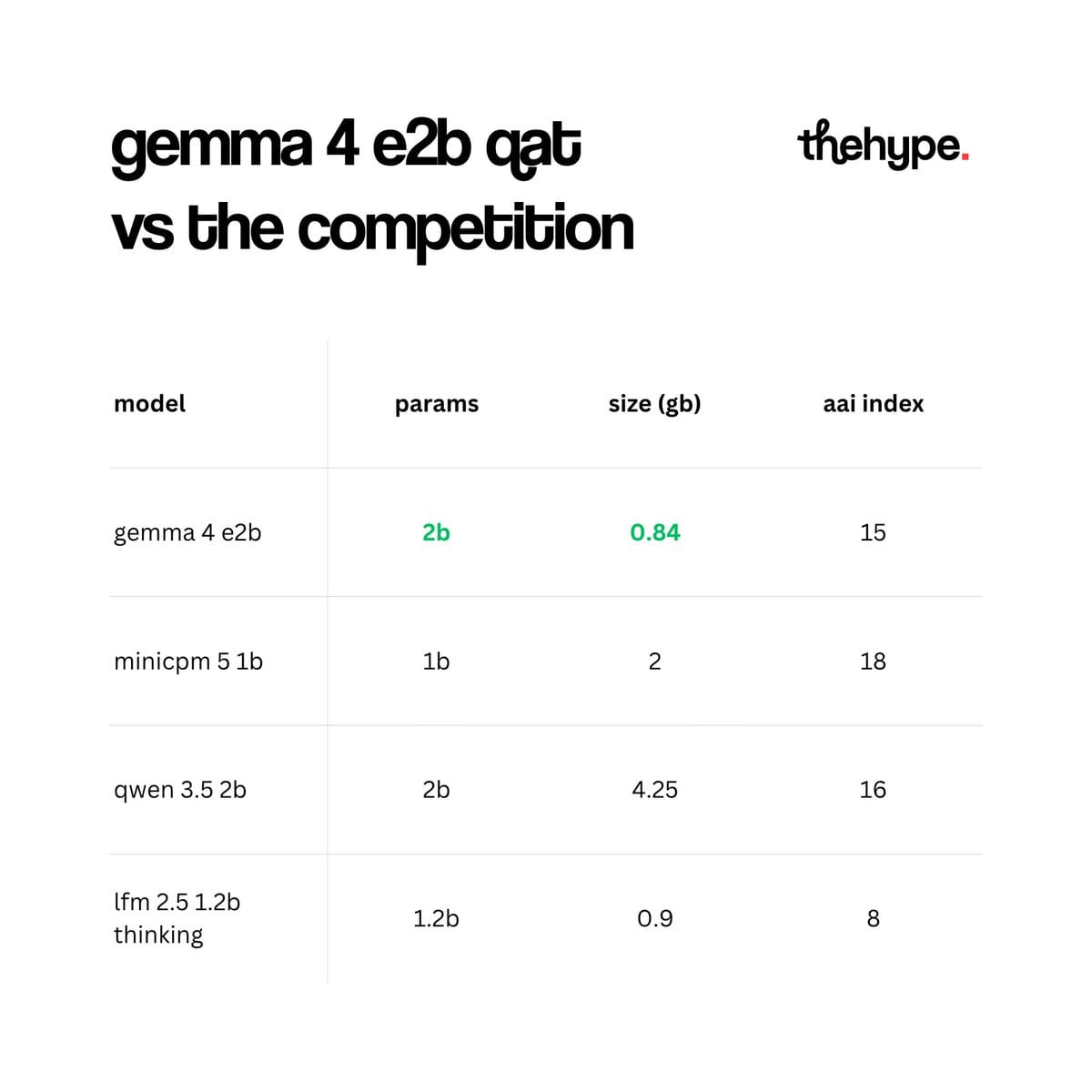
google keeps shrinking their open models
just released new versions of their gemma 4 ai models yesterday, optimized using a technique called quantization-aware training (qat)
how is qat different from normal compression?
normal compression (ptq) quantizes the model after training – which often hurts performance. qat bakes quantization into the training process itself, so the model learns to stay accurate even at smaller sizes.
the smallest model, gemma 4 e2b, has been squeezed down to 0.84 gb of memory in text-only mode. what's its normal size?
• full size gemma 4 e2b (bf16): 11.4 gb
• quantized gemma 4 e2b (q4_0 / 4-bit): 2.9 gb
• mobile version (qat): 1.1 gb
• mobile text-only version (qat): 0.84 gb
that's roughly a 91% reduction
what they did to get there:
- pre-calculated activation scaling instead of doing it on the fly
- structured data to fit mobile chip architecture natively
- compressed token generation layers to 2-bit while keeping reasoning layers higher precision
- optimized the vocabulary and short-term memory (kv cache) to allow longer conversations in less ram
at 0.84 gb, gemma 4 e2b qat is now the most lightweight model in its class. but here's the interesting part – qat is a technique, not a gemma exclusive. apply it to something like minicpm 5 1b (currently 2 gb) and you could shrink it even further